Multi-tenant Data Partitioning and Isolation
Many software-as-a-service (SaaS) applications store multi-tenant data with Storj. In addition, many Managed Service Providers (MSPs) and Value Added Resellers (VARs) leverage Storj to securely store data for their customers.
Storj supports multiple strategies for partitioning and isolating multi-tenant SaaS data. Typical implementations utilize a database abstraction layer when overlaying identity and access management constructs onto user data, but the underlying storage is managed based on the use case at one of three levels:
- Object Key Path Prefix
- Bucket
- Project
The selection of tenancy model for a given use case depends on the requirements primarily for access management, security and billing, but ultimately, Storj has the right set of tools to ensure that any multi-tenant application will be secure, scalable, performant and easily manageable.
This section describes the various strategies that can be applied when partitioning tenant data with Storj. For each of the different approaches, the considerations that may influence the approach that is appropriate for a particular solution type are highlighted.
If you’re not sure what the best approach is for your use case, please contact us and we’ll help with a recommendation for your architecture or an introduction to a Storj partner with expertise in this area.
Foundational Architectural Constructs
As a prerequisite, understanding the Storj information architecture is core to making an informed decision on an approach to multi-tenancy. In addition, understanding the principles for access management are essential for ensuring the appropriate level of tenant isolation.
Storj enables a number of different approaches to partitioning data for tenant isolation within a multi-tenant application. All data and metadata is stored in an encrypted state. The storj platform uses authenticated encryption in conjunction with erasure coding to ensure data is immutable when stored and cannot be changed independent of the metadata.
The encryption scheme uses hierarchically deterministic derived keys for both access and encryption. This makes it very easy to achieve tenant isolation in any of the configurations described below. This model enables tenants to view, interact with and share data within the scope of the defined data tenancy while providing strong security and privacy between tenancies. Figure 1 below describes the process for credential creation.
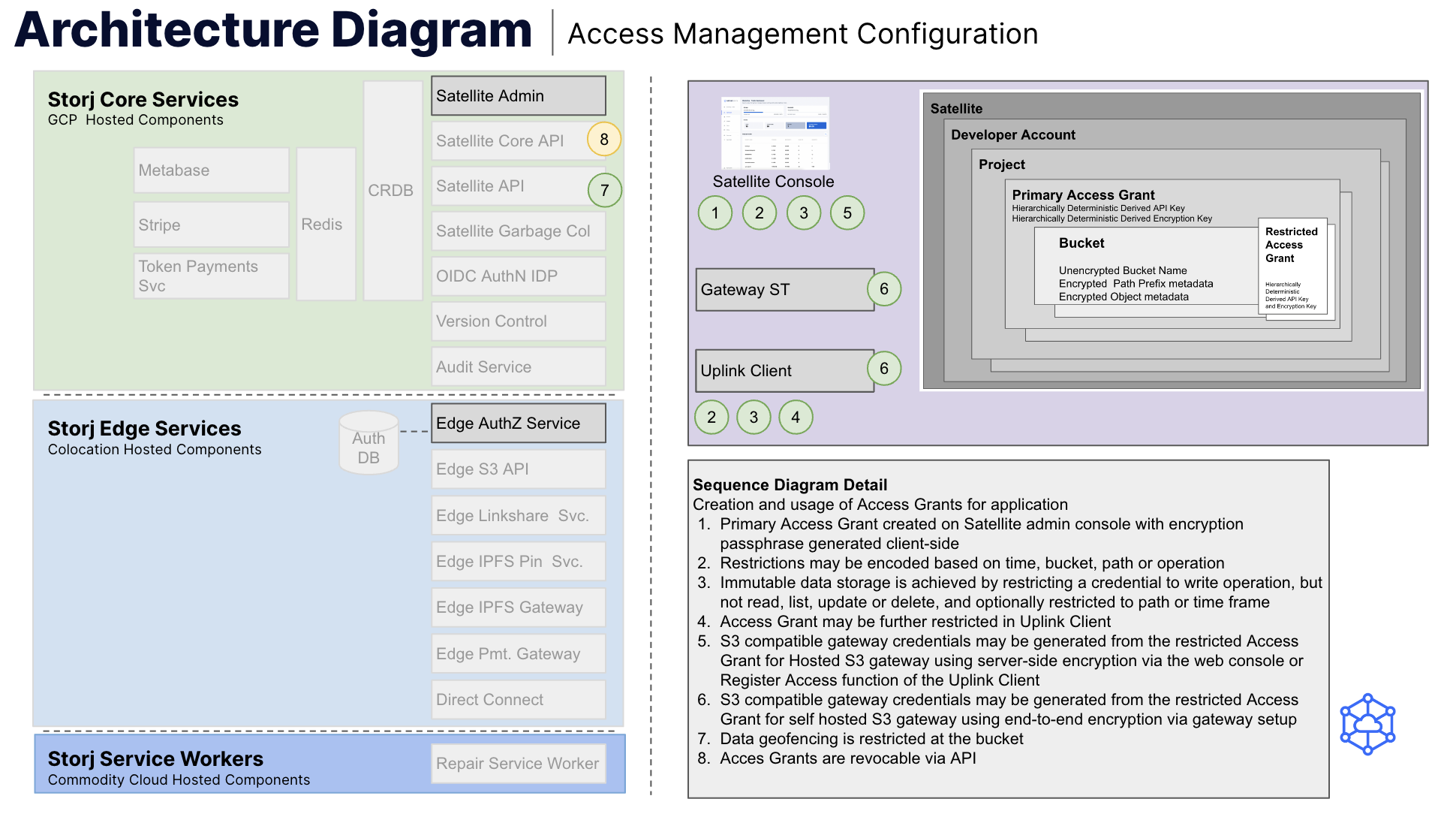
Figure 1: Storj access management configuration sequence diagram
Storj supports using common application access credentials within a multi-tenant application that provide full tenant isolation or creation of unique access credentials per tenant. Tenants may be configured to use unique encryption passphrases per tenant or hierarchically deterministic derived encryption keys. Note that when using the project per tenant model described below, unique credentials per customer are mandatory. Figure 2 below describes the process for tenant management using hierarchically deterministic derived keys.
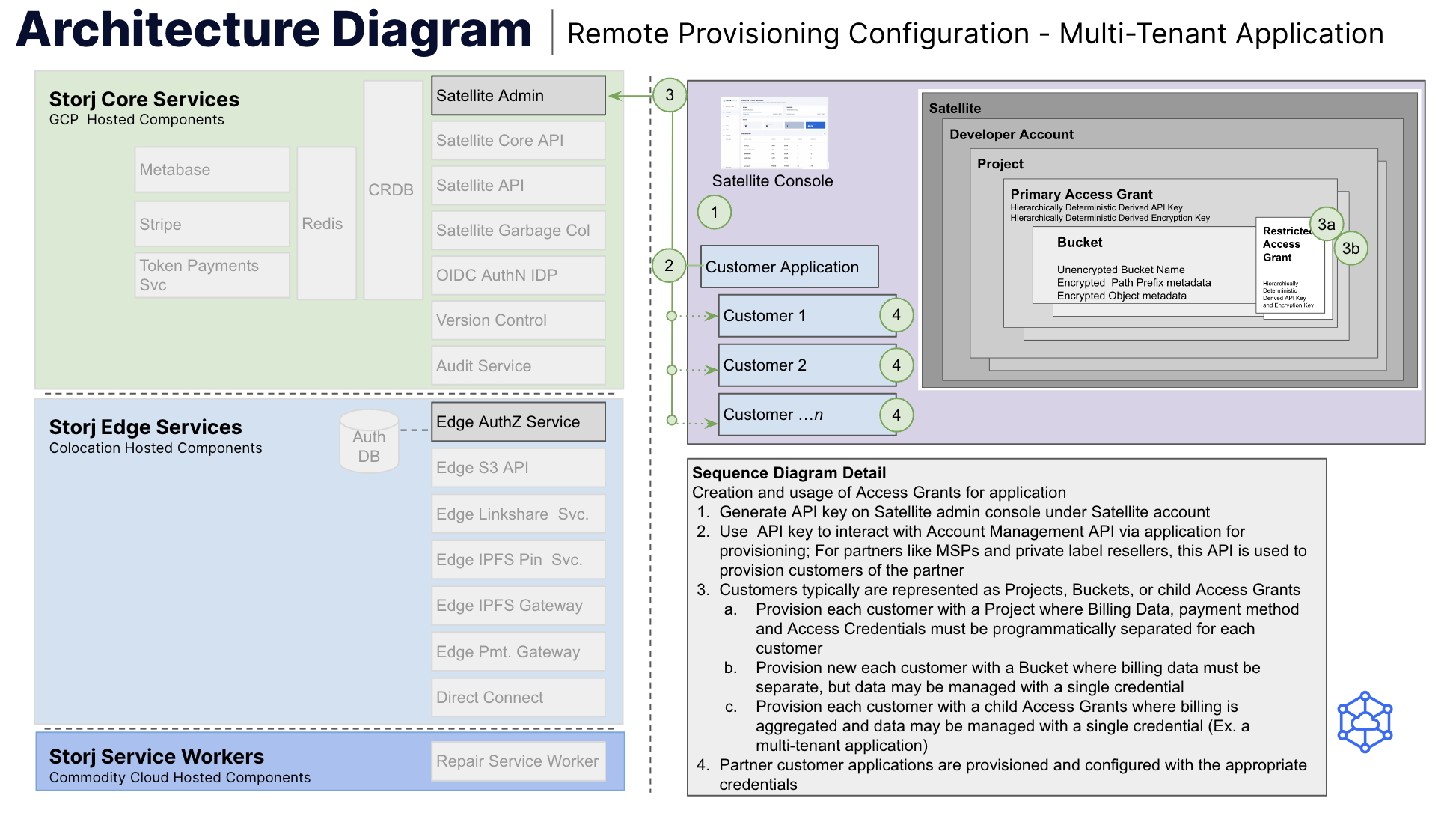
Figure 2: Remote provisioning sequence diagram for multi-tenant application with hierarchically deterministic derived credentials
All of the approaches below assume a simple data hierarchy where tenants are all defined at the same level as peers in the hierarchy. The Storj access management paradigm fully supports combining approaches for complex models that include sub tenancies.
Hierarchically deterministic derived credentials operate at the path prefix level and below, meaning that two credentials created for two path prefixes at the same level of a path hierarchy would not be able to perform operations between the two paths in the hierarchy. Each credential would have access to all data at any level below that path prefix within its respective path in the hierarchy if uploaded using that credential or any credential from which it was derived. This concept will be more clear with the examples provided below.
For assistance with design of complex access management models, please contact us and we’ll help with a recommendation for your architecture or an introduction to a Storj partner with expertise in this area.
Multi-tenant Application - Bucket per Tenant
The most straightforward approach to partitioning tenant data with Storj is to assign a separate bucket per tenant. The diagram below provides an example of this model.
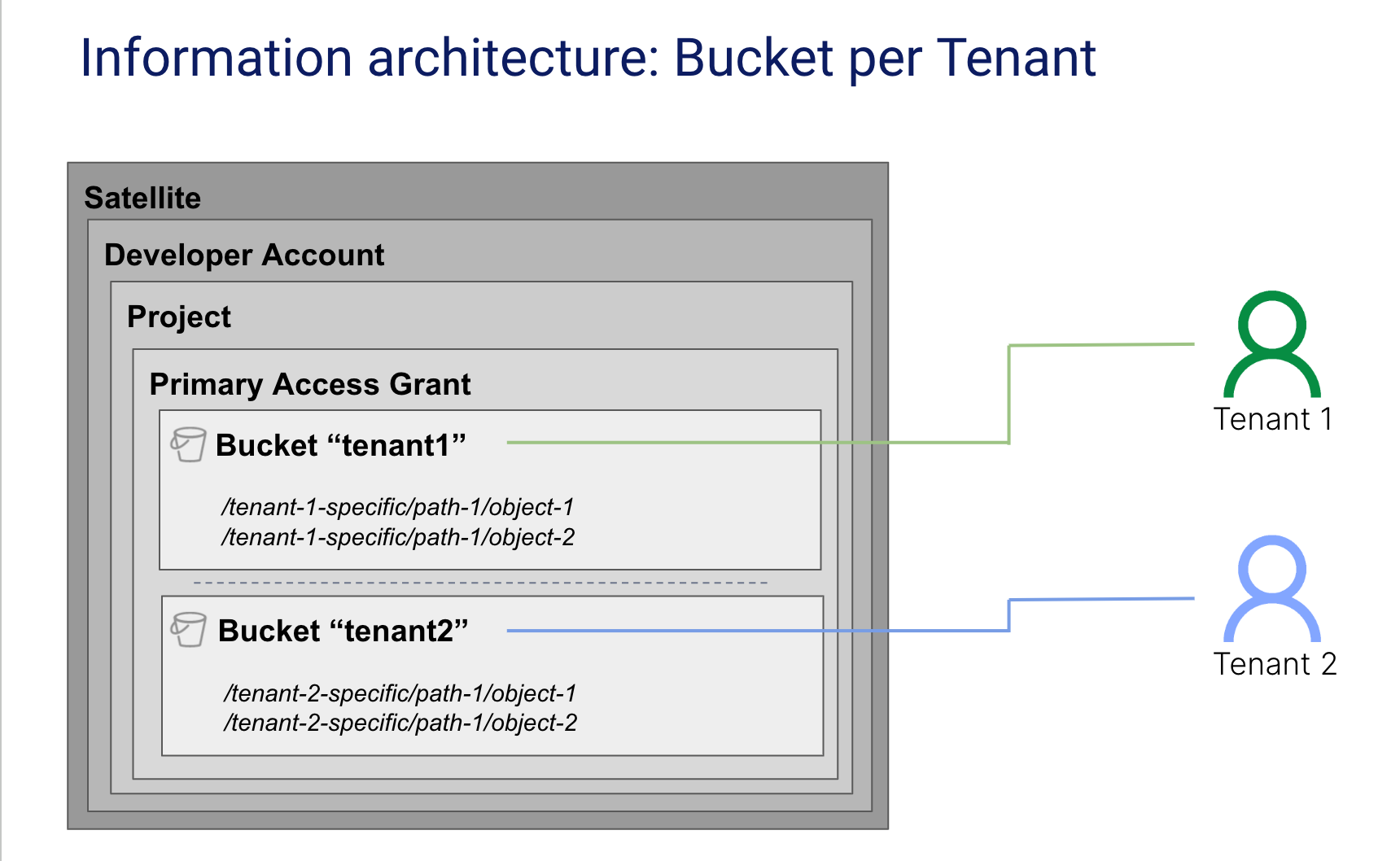
With this approach, each tenant would be assigned a bucket that holds its data. This bucket would be given a name that uniquely associates it with the tenant.
This model works well when you’re working with a smaller collection of tenants (tens or hundreds). However, it does not scale well for environments that need to support a much larger population of tenants. Storj has a default quota of 100 buckets and the hard quota of 1,000 buckets per Storj Project within an Account.
The other consideration here is bucket naming. Each bucket name must be unique within a Storj Project in your Storj account. A bucket-per-tenant model would require a naming convention that ensured your tenant bucket names would support this requirement. Since bucket names are public, they are not encrypted and you should generally avoid using names that include tenant-specific information.
Access management and tenant isolation is easy to achieve as separate credentials may be generated for client-side applications that are scoped per bucket. Separate encryption keys may also be used per tenant, but unless a common encryption key is used from which tenant encryption keys are generated, a common credential may not be used to access data across tenancies at an administrative level. When separate credentials are used per tenant, it is feasible to revoke a credential without impacting the validity of any other credential. Without a common encryption key across tenants, it is possible to aggregate information on an administrative level, such as listing all objects within the bucket (without decrypting their names), to count them and sum their sizes.
This model makes calculating usage per tenant straightforward as usage is itemized at the Bucket level within a Project.
Overall, while there is some simplicity to this model, it’s also clear the bucket-per-tenant model introduces challenges that could impact the scale and agility of your SaaS environment.
Summary of Bucket Per Tenant configuration:
- Solution Architecture: Tenant data in an application is stored in a single Bucket per tenant
- Provisioning: Each tenant represented as a Bucket where usage data is separate, but within the same Project
- Access Management: No tenant can access data of other tenants unless explicitly shared; An administrative Access Grant credential can perform any operation on any data in any bucket
- Security: Encryption passphrase is automated with hierarchically deterministic derivation; Bucket name is unencrypted for UI, so data that may potentially contain user identifiable data should be Object Key/ Path Prefix-based to ensure it is encrypted; Advance usage allows users to be allowed to choose encryption passphrase
- Billing: Usage is aggregated at the bucket level, invoicing is at the project level
- Restrictions: The default limit is 100 buckets per Project; the hard limit is 1,000 Buckets per Project; Separate Buckets may have different Placement Rules applied that restrict the storage nodes on which encrypted, erasure-coded pieces of data is stored associated with that Bucket
Multi-tenant Application - Object Key Path Prefix per Tenant
To achieve better scale and overcome some of the limitations of the bucket-per-tenant model, SaaS providers may use object key path prefixes to associate objects with tenants. This approach allows you to scale to a much larger collection of tenants without compromising on the structure or organization of your data partitioning scheme. The diagram below provides an example of this model.
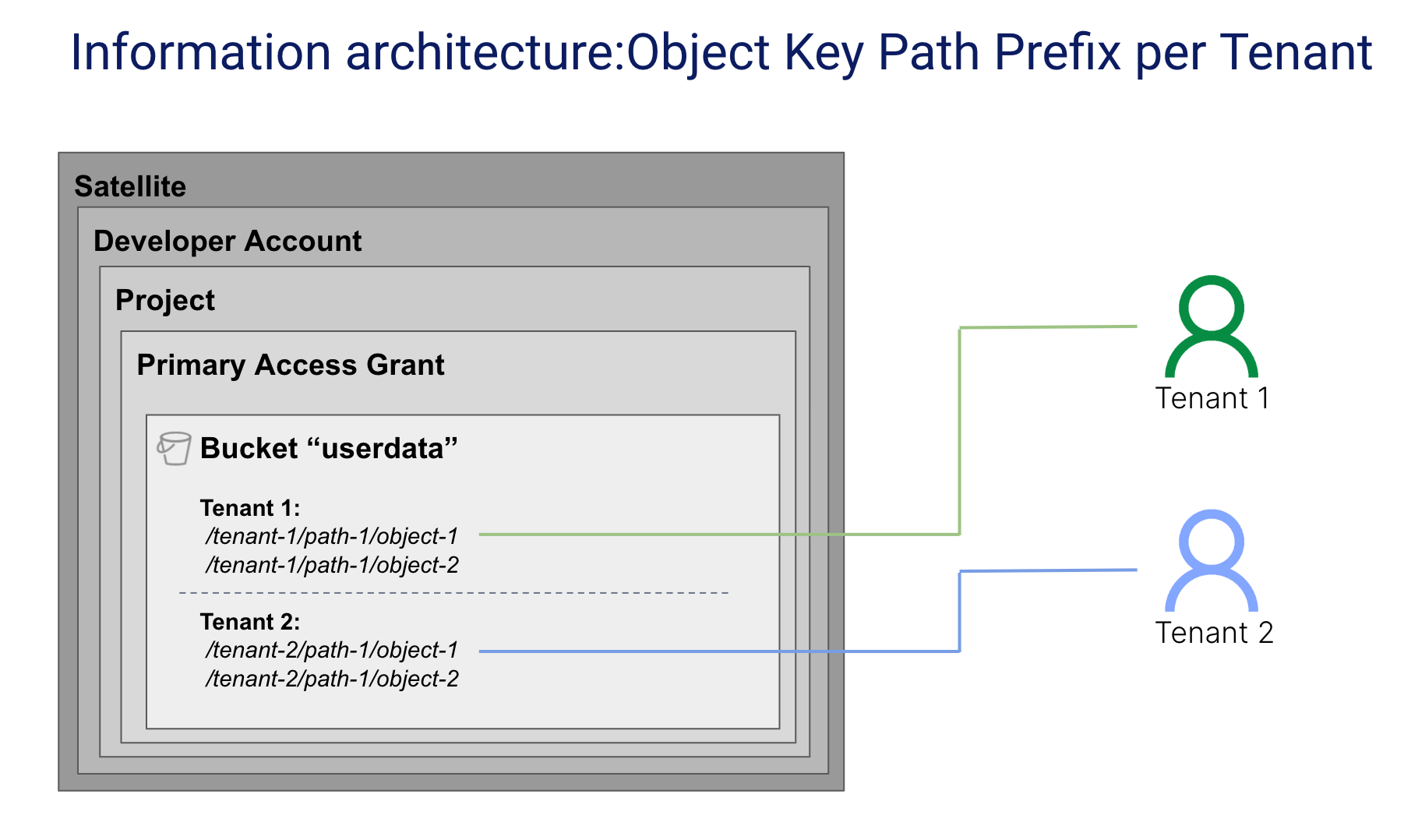
Here, you will notice that two tenants are sharing a single bucket. Each tenant has a unique prefix which identifies the objects that belong to that tenant. There is no limit to the number of objects you can store in a bucket or the number of prefixes you can have.
In this model, using tenant-identifying information in the Object Key Path Prefix is acceptable as all Object Key Path Prefix data is encrypted.
Note that it is possible to store data in an encrypted state but enable unencrypted metadata storage to support lexicographical sorting. Note that when using this option, it’s extremely important to be thoughtful about how authorization and access restrictions are implemented to avoid inadvertent disclosure of tenant-specific path-prefix information.
One challenge that can surface is that the activity for your S3 keys is unlikely to be evenly distributed across your tenants. In this model, you will need to separately monitor and meter usage per tenant. Storj does not aggregate usage information at the Object Key Path Prefix level.
This model scales best for multi-tenant applications with hundreds of thousands or millions of users.
Summary of Object Key Path Prefix per Tenant configuration:
- Solution Architecture: Tenant data in an application is aggregated and stored in a single Bucket
- Provisioning: Each tenant user within the application represented as a unique top-level path prefix and data for each tenant is stored in a single Bucket under that top-level path prefix
- Access Management: No tenant can access data of other tenant unless explicitly shared; An administrative Access Grant credential can perform any operation on any data
- Security: Encryption passphrase is automated with hierarchically deterministic derivation; Bucket name is unencrypted, but all path prefix based data that may potentially contain user data is encrypted; Advance usage allows users to be allowed to choose encryption passphrase
- Billing: Usage is aggregated at the bucket level, invoicing is at the project level
- Restrictions: There are no system limitations; Performance may be impacted if lexicographical listing of large numbers of users is required (1m+); Usage restrictions and metering are not available at the path prefix level limiting data available for metering or billing at the customer tenant level.
Multi-tenant Application - Project per Tenant
For the maximum level of tenant isolation, the Project per Tenant approach to partitioning tenant data with Storj provides a separate Storj invoice line per tenant and requires unique application access credentials per tenant. The diagram below provides an example of this model.
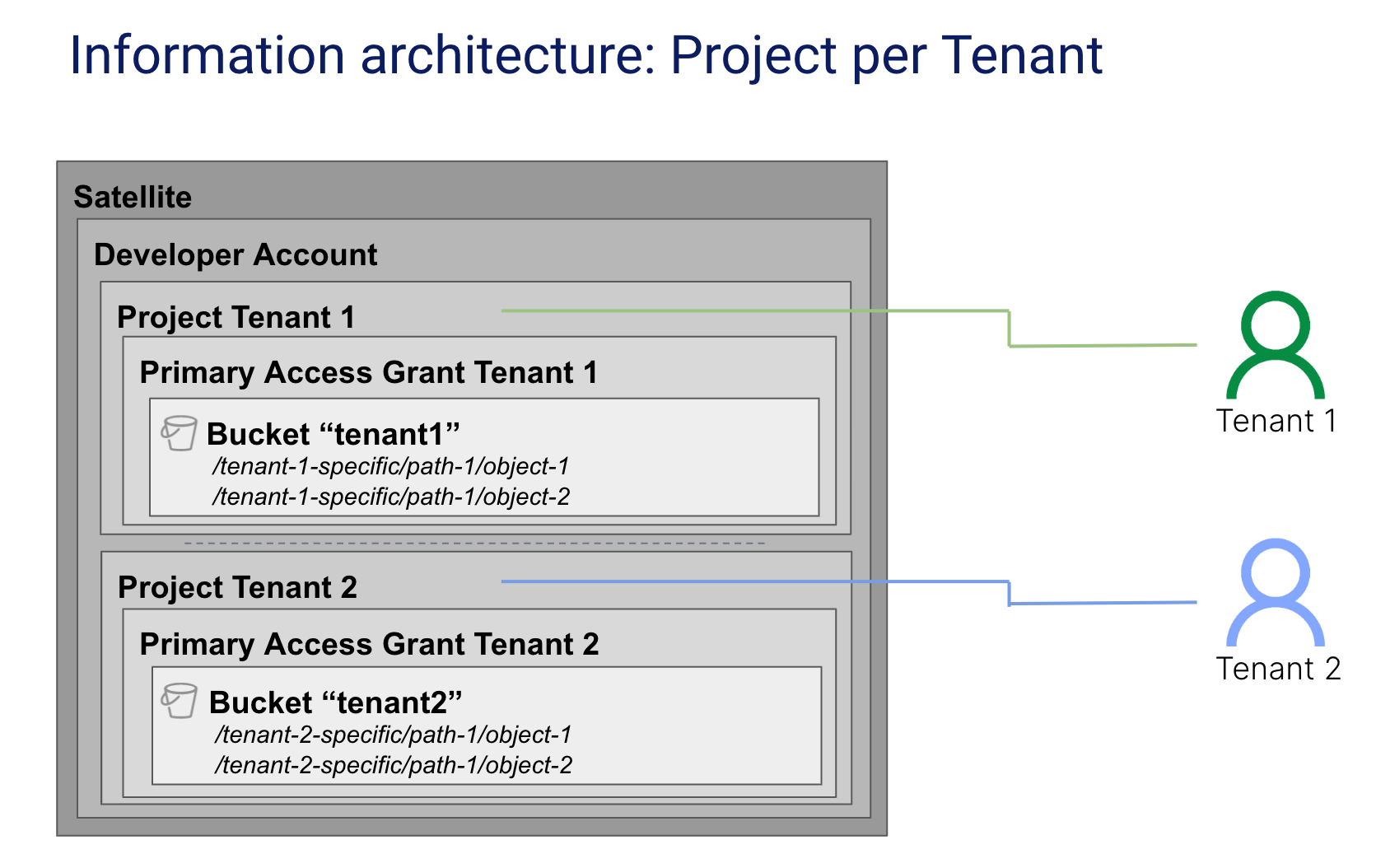
This format is most commonly used with Managed Service Providers or Value Added Resellers that are reselling storage as part of a bundled solution. In this structure each Tenant is defined as a Project on the Storj Platform. This model has the highest level of tenant isolation as it is not possible to create a single credential that can perform operations on data in more than one tenancy.
This model also provides the greatest level of flexibility to support Tenants that may be composed of Sub-tenants. A large enterprise may be represented as a Single Project, with multiple divisions represented as Buckets within that Project.
Projects may be migrated from one Storj Account to another making migration or offboarding responsibility for data management and billing from the MSP, VAR or Storj Customer directly to the Tenant for offboarding or other purposes.
Invoices are issued at the Project level within an Account. Billing information may be aggregated at the Account level via a the Solution Management API.
Summary of Project per Tenant configuration:
- Solution Architecture: Tenant data in an application is stored in a single Project per tenant
- Provisioning: Each tenant represented as a Project where usage, billing and access management are isolated per tenant; A management API is available for automation
- Access Management: No tenant can access data of other tenant unless explicitly shared; Tenants are logically isolated as it is not possible to create a single Access Grant credential that can perform operations on data in two different Projects
- Security: Encryption passphrase may be set at the Project level and is automated with hierarchically deterministic derivation; Project name is unencrypted for UI and invoicing, so data that may potentially contain user identifiable data should be Object Key/ Path Prefix-based to ensure it is encrypted; Advance usage allows granular encryption passphrase implementation at the Object-key or Bucket level
- Billing: Usage is aggregated at the bucket level, invoicing is at the project level
- Restrictions: The default limit is 3 Projects per Account; the hard limit is 80 Projects per Account; Separate Projects may have different Placement Rules applied that restrict the storage nodes on which encrypted, erasure-coded pieces of data is stored associated with Buckets in that Project
Tenancy Model Comparison Matrix
Tenant isolation is one of the foundational topics that every SaaS provider must address. It’s how your architecture ensures one tenant is prevented from accessing the resources of another tenant. Failure here would represent a significant and potentially unrecoverable event for a SaaS business.
As part of choosing a data partitioning model, you must also consider how a given partitioning model would influence the tenant isolation footprint of your solution. At any level, you can define tenant-specific restricted credentials that will be used to prevent cross-tenant access to resources using credential-specific path restrictions, operation restrictions, and encryption keys.
| Tenancy Isolation Model | Object Key Path Prefix | Bucket | Project |
| Best for | Multi-user/multi-tenant SaaS applications | Internal department data segmentation; Small MSP | Large MSP/VAR Reseller |
| Access Management | Each tenant can have unique S3 credentials that isolate the access to their data including a unique encryption key; A single credential set for all tenants may be created | Each tenant can have unique S3 credentials that isolate the access to their data including a unique encryption key; A single credential set for all tenants may be created | Each tenant must have unique S3 credentials that isolate the access to their data including a unique encryption key; A single credential set for all tenants may not be created |
| Security* | Hierarchically deterministic derived encryption passphrase per tenant | Bucket name not encrypted; Hierarchically deterministic derived encryption passphrase per tenant | Project Name not encrypted |
| Billing | Aggregated usage and billing | Metered Usage per BucketAggregated Billing | Metered Usage per Bucket Invoice per Project |
| Default Limits | 100m max objects per Bucket (based on Project limit) | 100 Buckets per Project | 3 Projects per account |
| Hard Limits | None | 1000 | 80 |
| Other Considerations / Restrictions | Lexicographical listing of Tenants not supported with default encryption | S3 Bucket naming restrictions applyPlacement rules available | Management API availablePlacement rules available |
Isolating and Ensuring Tenant Object Privacy with Encryption Keys
The tenant partitioning model of your SaaS solution may also be influenced by additional security considerations. While all data and metadata stored on the Storj platform is automatically encrypted with AES 256 GCM authenticated encryption, for some environments, the compliance and data sensitivity needs of an organization may require objects to be further protected through unique encryption keys per tenant.
Here, the focus is on how we can provide each tenant with a key that protects their data. In these scenarios, storj has a range of encryption capabilities supporting both server-side encryption as well as end-to-end encryption.
The tenant partitioning model you choose impacts how keys are applied. For example, with any model, the encryption scheme automatically provides encryption-based tenant isolation, but a single credential can be created to manage data across tenancies if required. You can assign a unique credential for each tenant with a unique, non-derived encryption key if that is required.
For assistance with design of complex encryption models, please contact us and we’ll help with a recommendation for your architecture or an introduction to a Storj partner with expertise in this area.
Solution Management API
Storj provides a set of API endpoints to support MSPs and VARs with service management. This API is available to Enterprise Customers and enables more sophisticated integrations with enterprise resource planning applications or customer provisioning workflows. The supported features for the Solution Management API are:
Project Management
- Create new Project
- Update Project
- Delete Project
- Get Projects
- Get Project's Single Bucket Usage
- Get Project's All Buckets Usage
- Get Project's API Keys
API Key Management
- Create API key
- Delete API Key
User Management
- Get User
For assistance with design of complex service delivery integrations, please contact us and we’ll help with a recommendation for your architecture or an introduction to a Storj partner with expertise in this area.
Additional Architectural Considerations
When planning multitenant architectures, Storj offers addional capabilities to provide more spphisticated solutions.
Node Selection, Node Groups and Placement Rules
Storj offers a set of features that enable identification, grouping and selection of a specific set of Storage Nodes to which storage of data may be restricted. In the context of multi-tenancy, this allows tenant data to be even further restricted at the storage node level. This capability unlocks use cases where tenant data is distributed across storage nodes running within a specific customer’s private infrastructure or other public cloud infrastructure (AWS, GCP, Azure, etc.). Read more about Node Selection, Node Groups and Placement Rules.
Private Label Solutions
Storj supports private label branded solutions for partners and customers. This service enables our partners to offer a multi-tenant branded object storage service that can include both infrastructure operated by Storj as well as partner infrastructure, including participation in the Storj Commercial Node Operator Program and a bring your own storage model (BYOS).