Decentralization
Decentralized data storage means more security and privacy. Decentralized cloud storage is more difficult to attack than traditional centralized data. On a decentralized network, files are broken apart and spread across multiple nodes. Storj uses Erasure Coding to distribute file pieces over many nodes located in different physical locations around the world.
There are more than a number of reasons why you may wish to utilize decentralized storage over legacy alternatives, namely:
Privacy & Security
Simple and economical pricing
Ease of integration
One of the main motivations for preferring decentralization is to drive down infrastructure costs for maintenance, utilities, and bandwidth. We believe that there are significant underutilized resources at the edge of the network for many smaller operators. In our experience building decentralized storage networks, we have found a long-tail of resources that are presently unused or underused that could provide an affordable and geographically distributed cloud storage.
Our decentralization goals for fundamental infrastructure, such as storage, are also driven by our desire to provide a viable alternative to the few major centralized storage entities who dominate the market at present. We believe that there exists inherent risk in trusting a single entity, company, or organization with a significant percentage of the world’s data. In fact, we believe that there is an implicit cost associated with the risk of trusting any third party with custodianship of personal data.
Unique Advantages of Decentralized Storage
Design Decision - End-to-end Encryption: the cryptographic technique of encrypting data on the sender's side, before it is transmitted to a server such as a cloud storage service. Client-side encryption features an encryption key that is not available to the service provider (in this case, Storj), making it difficult or impossible for service providers to decrypt hosted data. Client-side encryption allows for the creation of applications whose providers cannot access the data its users have stored, thus offering a high level of privacy. (Source: https://en.wikipedia.org/wiki/Client-side_encryption)
File Redundancy: In coding theory, an erasure code is a forward error correction (FEC) code under the assumption of bit erasures (rather than bit errors), which transforms a message of k symbols into a longer message (code word) with n symbols such that the original message can be recovered from a subset of the n symbols. The fraction r = k/n is called the code rate. The fraction k’/k, where k’ denotes the number of symbols required for recovery, is called reception efficiency. (Source: https://en.wikipedia.org/wiki/Erasure_code).
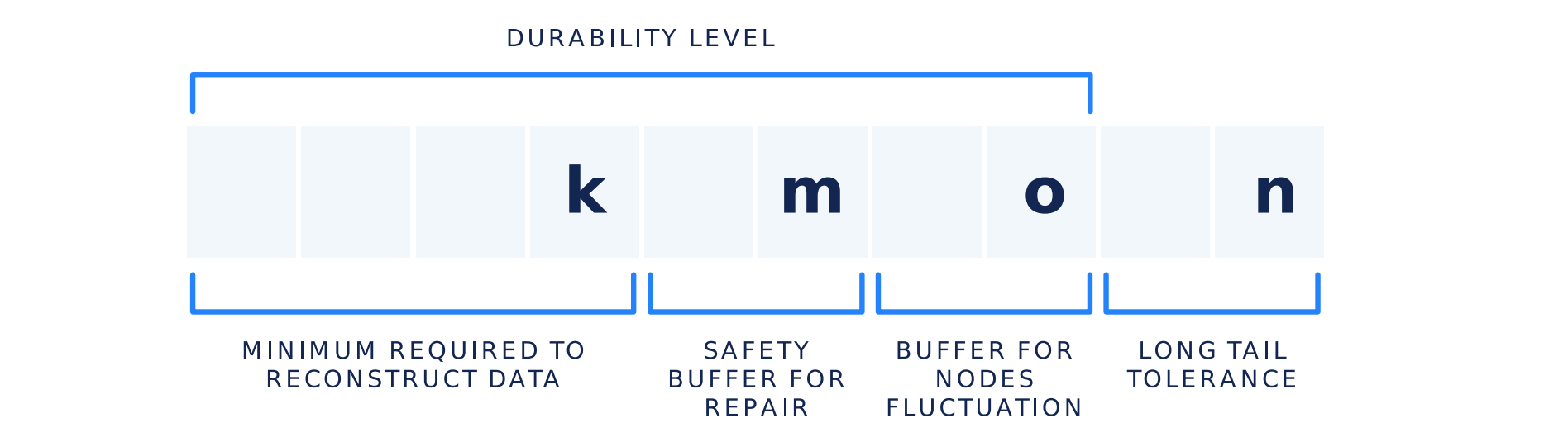
You can learn more about erasure codes in Storj under the File Redundancy section under Concepts.
Data Repair is necessary when the number of available pieces of a file still held on the network approaches the minimum threshold below which it would become impossible to recover the file. When we reach this threshold, the network will proceed to repair the data in such a way that the number of available pieces is always big enough to prevent the file from becoming irretrievable.
You can learn more about data repair in Storj under the File Repair section under Concepts.
File Audit is the action of testing if a random piece can successfully be retrieved from a node that is storing it. File Audits are continually applied to assure the durability of the files on Storj. The audit service is a highly scalable and performant analog to the consensus mechanism, typically a distributed ledger, used in other decentralized storage services.