Product Overview
Introduction
Storj makes open-source software that anyone can run - individuals with a Network Attached Storage Device or NAS, those with desktop computers that are always on, businesses, or data centers - that allows these users to share unused disk drive space and bandwidth with the network. Our software aggregates all of that storage capacity and bandwidth to create an extremely secure, private, and durable cloud storage service for developers.
Storj makes that storage and bandwidth available as a distributed cloud object storage service for developers, with an enterprise-grade 99.95% availability, eleven 9s of durability, and S3 compatibility under the Storj brand.
What is Storj?
Storj is an encrypted, secure, and affordable object storage service that enables you to store, back up, and archive large amounts of data to the decentralized cloud.
https://www.youtube.com/watch?v=JgKdBRIyIps
For developers who demand ownership of their data and who want to build with confidence, Storj is private by design and secure by default—delivering unparalleled data protection and privacy when compared to traditional centralized cloud object storage alternatives.
Storj offers affordable and predictable pricing, S3 compatibility, a robust library of open source technical documentation, and familiar development tools - along with a vibrant user community - which enables developers to economically and easily learn and leverage decentralized cloud storage technology to take control of their data when building the next great application or service.
Peer Classes
There are 3 main components, or peer classes, on the network - Storage nodes, the application that enables people to share excess hard drive capacity and bandwidth with the network, Uplink Clients, developer tools (sometimes hosted) to upload and download data, and finally, the Satellite, a hosted set of services that handles access management, metadata management, storage node reputation, and data repair, as well as billing and payment.
The Storage Node stores data for others, and gets paid for storage and bandwidth. All data stored on storage nodes is client-side encrypted and erasure-coded.
Uplink Clients enables developers to store data on Storj, handling end-to-end encryption from the client-side (by default), and erasure coding, where files are split into 80 pieces then distributed across our network of storage nodes. Each of the 80 pieces is stored on different, diverse storage nodes, with different operators, power supplies, networks, and geographies, etc. - yielding tremendous security, performance, and durability advantages. The client-side managed, end-to-end encryption combined with our edge-based access management capabilities provide easy-to-use tools for building applications that are more private, more secure, and less susceptible to a range of common attack vectors. Uplink clients include both our self-hosted and Storj-hosted S3 compatible gateways, the CLI, and the libuplink Go library and bindings.
The Satellite is a set of hosted services that handles developer account access, API access management, metadata management, storage node reputation, data audit, and data repair, as well as billing developers and payment for Storage Nodes. Storj Labs satellites are operated under the Storj brand.
How it's Different
To give you a sense of how the Storj service is different, it’s helpful to describe what happens with a round-trip upload and download of a file. Files are uploaded using an Uplink client, whether directly using the CLI or S3 compatible gateway, or indirectly using a tool that has integrated the libuplink library, such as FileZilla, Rclone or Restic.
What Happens When You Upload
When a file is uploaded, it’s first encrypted by the Uplink client using an encryption key held by that client. Next, it’s erasure-coded, meaning it’s broken up into pieces, of which only a subset are required to reconstitute a file. The redundancy from erasure coding is far more efficient than replicating files and this technology used by most data storage systems, including DVDs, which is why you can still watch a movie even if there are scratches and fingerprints on the disk.
For example, we may need 29 of the 80 pieces we uploaded.
The Uplink Client then contacts the satellite to get a list of Storage Nodes on which to store the pieces. The satellite returns more than 80 Storage Node addresses. The Uplink Client uploads pieces peer-to-peer, in parallel, directly to the Storage Nodes. The Uplink client stops attempting to upload pieces once 80 pieces have been successfully uploaded to at least 80 Storage Nodes.
The Uplink Client attempts a few more than 80 during the upload process to eliminate any long-tail effect and the related latency from the slowest Storage Nodes.
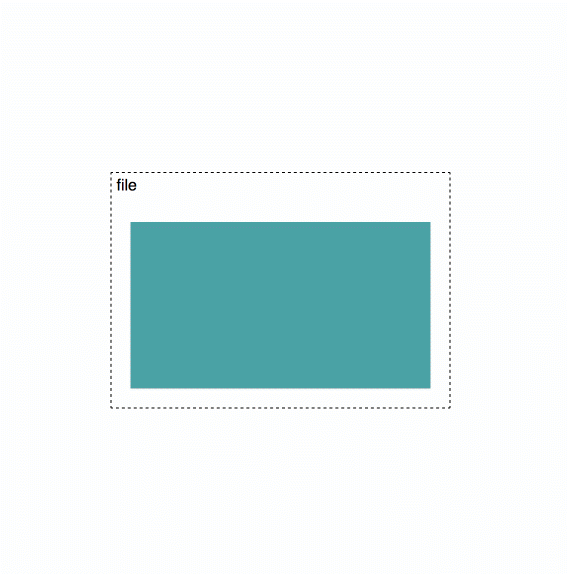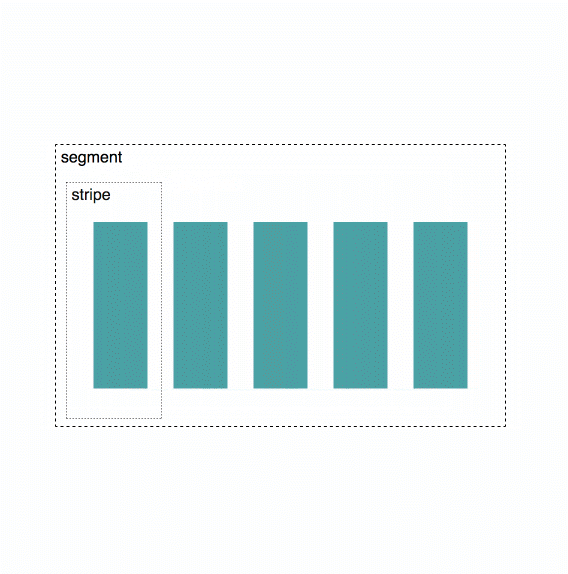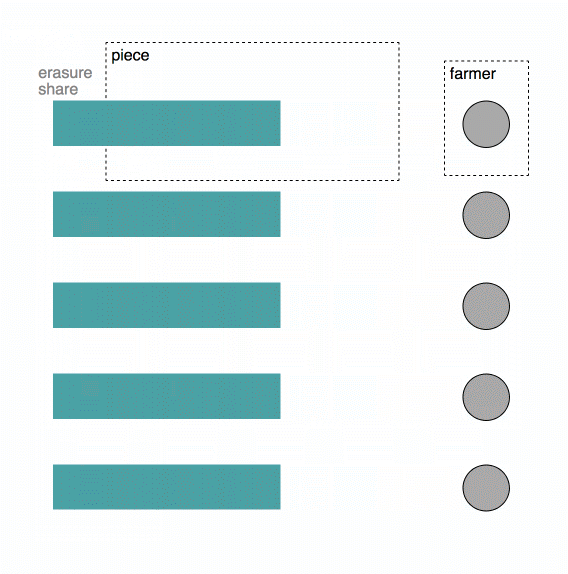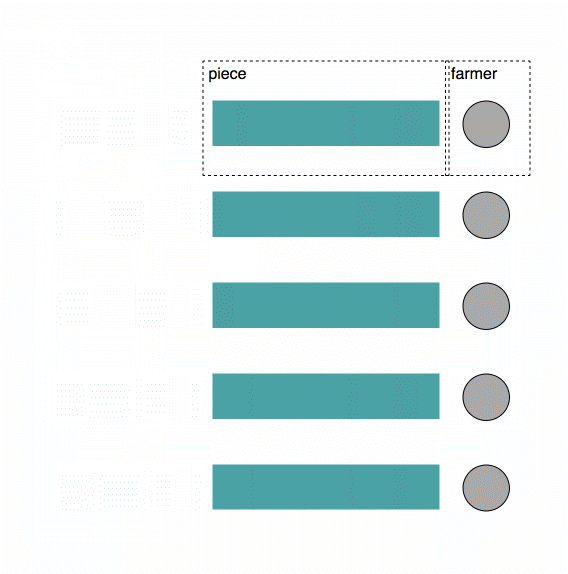
What Happens When You Download
When the Uplink Client downloads a file, it’s essentially the same process as an upload but in reverse. The Uplink Client requests a file from the Satellite and the Satellite returns a list of Storage Nodes from which the Uplink Client can retrieve the pieces of the file. The Uplink Client starts attempting to download pieces from the given Storage Nodes, again, stopping once it has retrieved the required pieces needed to reconstitute the file after eliminating latency from the long-tail effect. The pieces are re-encoded and then decrypted by the Uplink client as only it has the encryption key.
Why Developers Love Storj
Even with the sophisticated privacy and security features and the default multi-region availability, developers love Storj because it's extremely easy for them to get started and build more secure and private applications.
When uploading and downloading files, a developer or app issues a simple cp command - the Uplink Client does the rest, abstracting all of the complexity of encryption, erasure coding, and distributing pieces on storage nodes to the Storj software in the background.
What's more, developers can use the Satellite Admin Console web interface or the share command with one either our CLI or developer library/SDK to abstract all the complexity of granular access management via client-side delegated authorization.
Features
Developers have a wide range of choices for S3-compatible object storage, but Storj provides a number of key advantages to help developers build more secure and private applications:
🛡 Security
Confidently store your data with files split, distributed, and stored multi-regionally across the globe providing no single point of failure, resistance to hacking, tampering, and bitrot, and an edge-based security model.
🔓
Privacy
Own your data with default encryption and user-assigned access grants so no one can view or compromise your data without permission.
🔌
Plug-in S3 Compatibility
Swap out a few lines of code, and you’ll be up and running in minutes.
☁️
Availability
Download your data anytime you need it with multi-region architecture, no single point of failure, and satellite-automated data orchestration. No downtime, no bitrot, and no lost files.
🛠
Durability
Automate file repair and know that Reed-Solomon erasure coding enables the highest levels of durability for all files uploaded to Storj.
💰
Cost Efficiency
Get high availability multi-region cloud object storage for a fraction of the price of a single availability zone from centralized providers like AWS.
📂
Open Source Freedom and Flexibility
Take advantage of absolute transparency through our open source code. You are not locked-in to our technology or cost structure - giving you the freedom of choice.
💬
Community Driven
Share, discuss and collaborate with other open source developers in the Storj community and find answers to questions in our very active forum.