Immutability
Immutability
A number of object storage use cases require storage of data in a manner that the data is verifiably unalterable and incapable of being deleted. Use cases under this category include providing ransomware-resistant storage/backups or storage of data that is covered by regulatory frameworks such as HIPAA.
Storj provides a unique combination of technologies that enable customers and partners to store data in a secure manner that achieves the goal of indeterminate preservation with immutability. This documentation covers the foundational technologies and their usage in the following other sections:
This section will describe how those foundational technologies and the associated features are implemented to achieve data immutability.
For more information on implementing Write Once, Read Many (WORM) storage see here
Defining Immutability
Immutability in data storage may be broadly defined as providing a set of controls that ensure data may not be altered or deleted except under a specific set of circumstances and via credentials created by specific, authorized users. Data that has been configured for immutable storage is by definition read-only, meaning that it cannot be lost, accidentally deleted, corrupted, subjected to cyberattacks or ransomware, deliberately or inadvertently altered or otherwise left vulnerable to issues that can compromise the data. Immutable storage ensures the provenance and authenticity of data and provides reliable and dispositive data recovery for essential data.
Background
All cloud object services achieve data immutability by managing a combination of three basic security constructs:
Privileged Identity Management / Privileged Access Management (PIM/PAM)
Credential Authorization Management
Data Storage Infrastructure Security
These factors provide layers of security for data storage. Achieving data immutability starts with restricting who has the access to create credentials, security policies and configurations that determine the conditions under which data may be modified or deleted. The next layer is to establish the technical enforcement points to ensure that specifically limit application interactions with immutable data such that data cannot be altered or deleted. Finally, the underlying storage infrastructure must be secured in such a manner as to prevent the inadvertent or deliberate circumvention of access management controls or technical enforcement points via a brute-force attack on physical infrastructure.
Storj Security Constructs
Storj has implemented a range of security constructs to ensure that immutable data storage may be achieved on the storage service. Where appropriate, Storj has implemented industry best practices and provided a compatibility layer with existing technical approaches to immutability. Storj has also introduced several unique capabilities that reduce the complexity required to secure data while reducing the risk and impact associated with the most common attack vectors to immutable data.
Privileged Account Management
Storj follows industry best practices to secure user accounts that have privileged levels of access to interact with immutable data. Storj offers multi factor authentication (MFA) that enables users to address the risks associated with unauthorized access to user accounts.
While enabling MFA on privileged accounts is the industry norm and best practice for restricting access management for authorized users, Storj adds an additional layer of protection for immutable data. Since all data and metadata is encrypted with encryption keys that are managed by the user and that are not stored on the Storj service, even if a privileged user account is compromised, unless the encryption passphrase associated with the data is also compromised, access to the actual data is not possible.
Credential Authorization Management
While it is important to secure privileged user accounts, by far the most common attack vector on cloud storage repositories are credential-based attacks. Credentials created for applications to interact with cloud storage are frequently embedded in application configurations in SaaS applications or installed applications on servers. If those Saas applications or hardware devices are compromised and a bad actor is able to access a credential, that bad actor may do whatever the credential is authorized to do. In all cases, the bad actor will attempt to escalate the privileges associated with the credential, either by bypassing additional environmental restrictions such as security policies on a specific environment or using the credential in a different application, environment or security context. Moreover, where the implementation of security controls requires a high level of complexity, users frequently choose not to implement the full spectrum of security options due to the high level of friction introduced into development lifecycles.
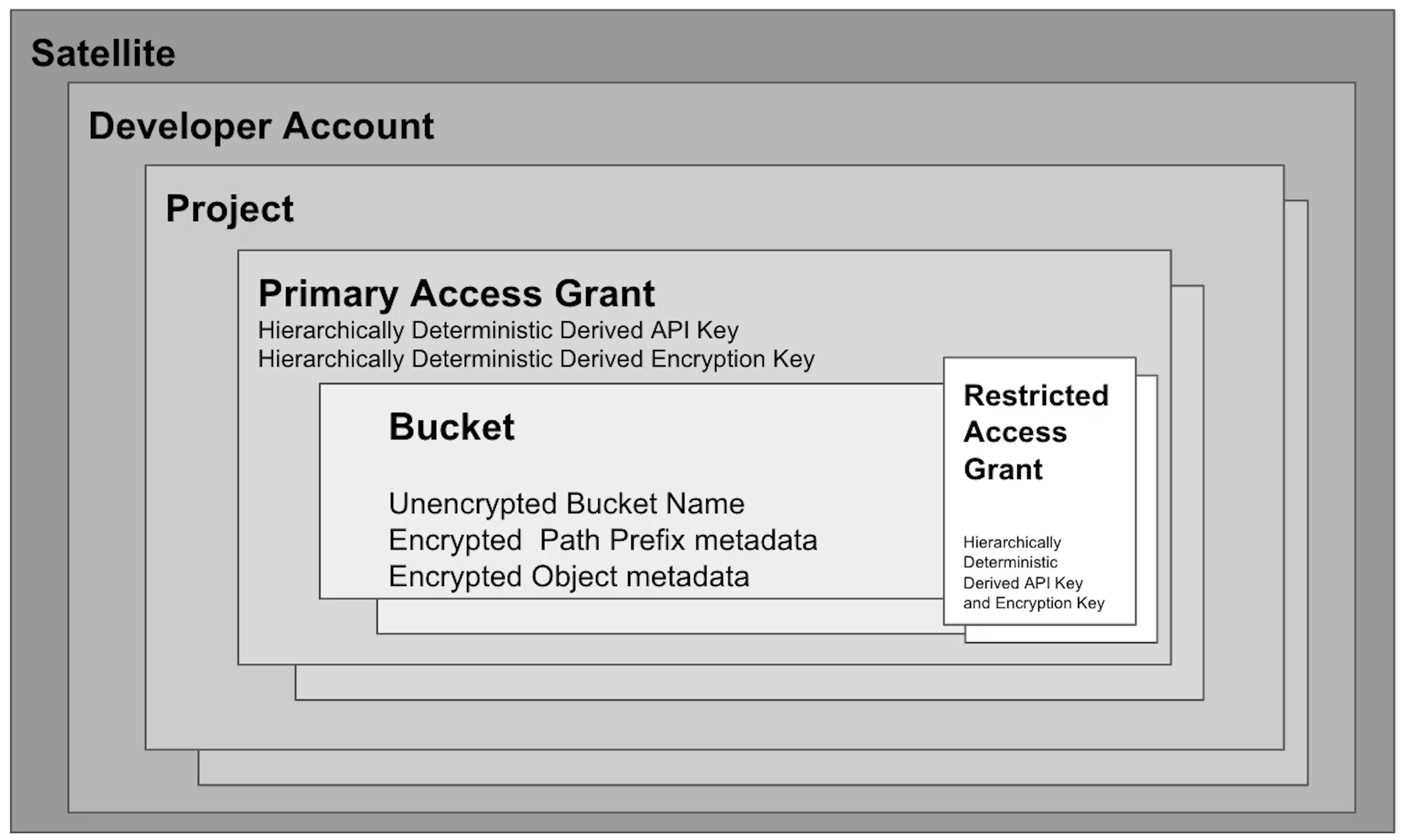
Storj significantly simplifies the process of securing credentials and restricting the attack surface through the use of API Keys based on Macaroons. Access restrictions are encoded into API Keys within and Access Grant automatically upon creation via the Satellite Admin Console, via the CLI, or libuplink library, when using the Share command. While the possibilities for access controls that can be encoded in a Caveat are virtually unlimited, the specific Caveats supported on Storj today are as follows:
Specific Operations: Caveats can restrict whether an Access Grant can permit any of the following operations:
Read
Write
Delete
List
Bucket: Caveats can restrict whether an Access Grant can permit operations on one or more Buckets.
Path and path prefix: Caveats can restrict whether an Access Grant can permit operations on Objects within a specific path in the object hierarchy.
Time Window: Caveats can restrict when an Access Grant can permit operations on objects stored on the platform (before or after a date and time or a range of time between two dates/times
Once these restrictions are encoded into an API Key, they cannot be increased in scope. Restrictions are encoded and signed with an HMAC signature. Additional keys may be created from an API Key, but API Key creation follows a hierarchically deterministic key derivation scheme which means that the capabilities of a new API Key derived from a parent API Key may only have the same level of privilege or lower. Any privilege escalation attack that attempts to increase the capability associated with an API Key will fail as the validity of any API Key is cryptographically verifiable, and the HMAC signature of a modified API Key will not match and the Key will be rendered invalid.
Data Storage Infrastructure Security
While attacks on storage infrastructure are the least common, failure of storage hardware remains a real concern when it comes to the viability of immutable data. Storj take a unique approach to storing data with default encryption, erasure coded redundancy, and highly distributed storage. The result is that all data is highly available and resistant a wide range of infrastructure failures while retaining a high level of durability that is both cryptographically verifiable, subject to automated integrity checks via cryptographic audits and able to be repaired in the event that some portion of the infrastructure fails or is otherwise compromised. There are 6 key components and processes that provide for data integrity despite any failure of underlying hardware infrastructure.
Encryption
All object data and metadata are encrypted by default on the Storj service. Objects are broken into segments and segments are encrypted using a randomized salted encryption passphrase, and the randomization ensures that if data was extracted from the underlying storage hardware, a bad actor would only be able to acquire encrypted data with no access to encryption information. Larger objects broken into multiple segments would require breaking multiple individual encryption keys even for a single object. Any attempted modification of a segment would be impossible due to the storage of data in an encrypted state.
Erasure Coding
Encrypted object data is broken into 64MB segments and then erasure coded using a 29/110 Reed-Solomon erasure coding scheme. Erasure coding ensures the integrity of data in several ways. The unit of storage of data on Storj is an erasure-coded piece of an encrypted object segment. Any attempt to modify a piece of data stored on Storj would invalidate the cryptographic signature of the piece effectively rendering it unreadable and unavailable. Erasure coding also introduces a high amount of redundancy into the storage layer such that 51 pieces of any segment could be lost simultaneously without impacting the durability of that segment.
Data Distribution
The Reed-Solomon erasure coded pieces of data are distributed over a network of tens of thousands of storage nodes in a manner that ensures that no two pieces of an object segment are stored on the same node. If any piece of hardware or infrastructure on the service fails or becomes unavailable, including hard drives, servers, equipment racks, whole data centers, or even whole regions, the integrity of data storage is not impacted. Loss or corruption of immutable data would require that huge numbers of independently operated equipment owned by different operators, on different networks, with different power supplies and in different geographical locations fail simultaneously.
Data Verifiability
Since data is stored on the distributed network of hardware in an encrypted and erasure coded state, it is impossible to modify data while stored at rest on the network. Data must be retrieved, re-encoded, decrypted, modified, re-encrypted, encoded, and distributed. Due to the encryption methodology, metadata for the modified data cannot be independently edited to allow immutable data to be modified. Any piece or segment of data may be cryptographically verified to determine its authenticity.
Audit
All data is subject to constant statistical audits that test small byte ranges of objects to ensure that storage hardware is successfully storing pieces of data. The audit process ensures that the service is able to verify the availability and durability of data at all times. As hardware fails or nodes are rendered offline, the system keeps track of the number of pieces of segments on the system to ensure the minimum number stays above a predetermined threshold for viability, known as the repair threshold.
Repair
If the number of pieces of any segment reaches the repair threshold, the system determines that the durability of that piece is approaching the minimum level of eleven nines of durability. The service then repairs the missing pieces and redistributes them to healthy storage nodes to ensure long term viability of immutable data.
Practical Implementation Pattern
Using cloud object storage for an uncorrelated backup is one of the most common ways of avoiding the risk of data loss through hardware failure or exposure to threats associated with ransomware or malware. Many approaches use features like S3 Object Lock or overlaying security policies on servers, but Storj offers an effective alternative that is complex to implement, but provides an equivalent or greater level of protection.
Immutability Via Operation Restriction Encoded in Credential
Storj access credentials include an API Key that can include caveats (conditional access restrictions that are encoded into the body of an API Key) which limit the operations that the API Key can allow an application to execute.
An API Key has three parts, a head, a list of caveats, and a tail. These are concatenated and serialized together. An unrestricted API Key has no caveats, so it’s just a head and a tail. The head is a random nonce, and the tail of the unrestricted API Key is the HMAC of the root secret and the head.
Creating a credential to achieve immutability is simply a matter of limiting the credential so that it can accomplish only the job it is intended to do with the least privilege, in this case back up application data. The credential should not have the capability to view data, update data, or delete data. The credential should be write-only.
In this case, the credential should be created to allow writes, but disallow reads, lists, reads and deletes. Restricted credentials can be either created as an Access Grant for native integrations or as S3 compatible gateway credentials. Credentials can be created from the Satellite Admin console or via the Storj CLI. A write-only credential may also be limited based on the timeframe for which it is valid and may also be restricted to a specific bucket, path key or object key. The documentation for creating a restricted access credential may be found:
Once the write-only credential has been created, it is not possible to modify the credential to add additional operations, paths or objects to which the credential has access, or otherwise increase the scope of privilege. While a credential may be used to create a child credential with the same or less scope of privileges, the scope can never be increased. Properly created restricted credentials are fixed as of the int in time of creation and may not be altered to escalate privilege.
When an application is configured with the write-only operation, any application configured with that credential can only write new data. Pre-existing data may not be overwritten, viewed, listed or deleted. The data is effectively immutable.
If the application configured with the credential or the actual credential is compromised, it may only be used to impact future data writes (i.e. backups created after the date that the application/credential was compromised) ensuring that any data written prior to that time is not impacted.
Ransomware Recovery
When networks or systems are compromised and a bad actor seeks to extract payment in exchange for the return of that data or control of systems, typically, the fastest path to recovery is an immutable, uncorrelated cloud backup.
A user with privileged access may create a new credential with the capability of reading the backup. Typically this recovery credential is created as read-only restricted to list and read operations so that the backup can be recovered and systems restored, but in the event recovery steps are taken from a machine that is unknowingly or subsequently compromised, the recovery credential may not be used in a separate attack.
If the recovery environment is suspected to be compromised or there is a risk that the data could be exposed, data may be recovered in its encrypted state and subsequently decrypted in an air-gapped or otherwise secured environment.
Applicability to AI Training Sets
Another emerging use case for immutable data is for training sets or fine tuning data sets for artificial intelligence (AI) or machine learning (ML) models. Models are resource-intensive to train and immensely valuable, but the provenance of the underlying training datasets are key to protecting the value of those models.
Using Storj as the storage service for AI and ML datasets ensures the underlying data remains immutable so that future analysis of the source for any model remains fully traceable and auditable. Moreover, data sets can be moved at high speed to any point on the globe regardless of where the compute resources are located. The combination of immutable storage and the distributed architecture ensure that enterprises are able to leverage the most cost-effective compute resources in conjunction with secure, performant object storage.