File Redundancy
Durability and expansion factor
In a decentralized storage network, any storage node could go offline permanently at any time. A storage network’s redundancy strategy must store data in a way that provides access with high probability, even though any given number of individual nodes may be in an offline state. To achieve a specific level of durability (defined as the probability that data remains available in the face of failures), many products in this space (Filecoin, MaidSafe, Siacoin, GFS, Ceph, IPFS, etc.) by default use replication, which means simply having multiple copies of the data stored on different nodes.
Unfortunately, replication anchors durability to the network expansion factor, which is the storage overhead for reliably storing data. If you want more durability, you need more copies. For every increase of durability you desire, you must spend another multiple of the data size in bandwidth when storing or repairing the data, as nodes churn in and out of the network.
For example, suppose your desired durability level requires a replication strategy that makes eight copies of the data. This yields an expansion factor of 8x, or 800%. This data then needs to be stored on the network, using bandwidth in the process. Thus, more replication results in more bandwidth usage for a fixed amount of data.
On the one hand, replication does make network maintenance simpler. If a node goes offline, only one of the other storage nodes is needed to bring a new replacement node into the fold. On the other hand, for every node that is added to the redundancy pool, 100% of the replicated data must be transferred.
Erasure Code
Erasure codes are another redundancy approach, and importantly, they do not tie durability to the expansion factor. You can tune your durability without increasing the overall network traffic!
Erasure codes are widely used in both distributed and peer-to-peer storage systems. While they are more complicated and possess trade-offs of their own, the scheme we adopt, Reed-Solomon, has been around since 1960 and is used everywhere from CDs, deep space communication, barcodes, advanced RAID-like applications–you name it.
An erasure code is often described by two numbers, k and n. If a block of data is encoded with a k, n erasure code, there are n total generated erasure shares, where only any k of them are required to recover the original block of data! It doesn’t matter if you recover all of the even numbered shares, all of the odd numbered shares, the first k shares, the last k shares, whatever. Any k shares can recover the original block.
If a block of data is s bytes large, each of the n erasure shares are roughly s/k bytes. For example, if a block is 10 MB, and you’re using a k = 10, n = 20 erasure code scheme, each erasure share of that block will only be 1 MB. This means that with k = 10, n = 20, the expansion factor is only 2x. For a 10 MB block, only 20 MB total is used, because there are twenty 1-MB shares. The same expansion factor holds with k = 20, n = 40, where there are forty 512-KB shares.
Interestingly, the durability of a k = 20, n = 40 erasure code is better than a k = 10, n = 20 erasure code, even though the expansion factor (2x) is the same for both. This is because the risk is spread across more nodes in the k = 20, n = 40 case. To help drive this point home, we calculated the durability for various erasure code configuration choices in a network with a churn of 10%. We talked more about the math behind this table in section 3.4 of our paper, and we’ll discuss more about churn in an upcoming blog post, but suffice it to say, we hope these calculated values are illustrative:
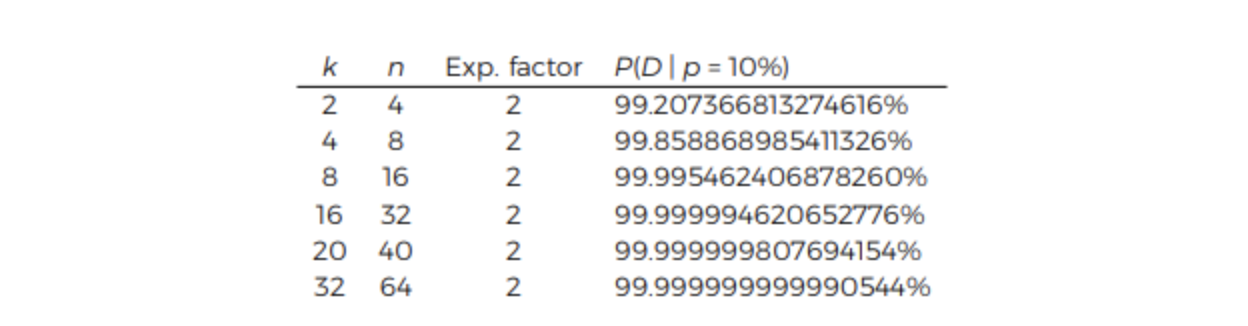
Notice how increasing the amount of storage nodes involved increases the amount of durability significantly (each new 9 is 10x more durable), without a change in the expansion factor. We also put this data together in a graph:
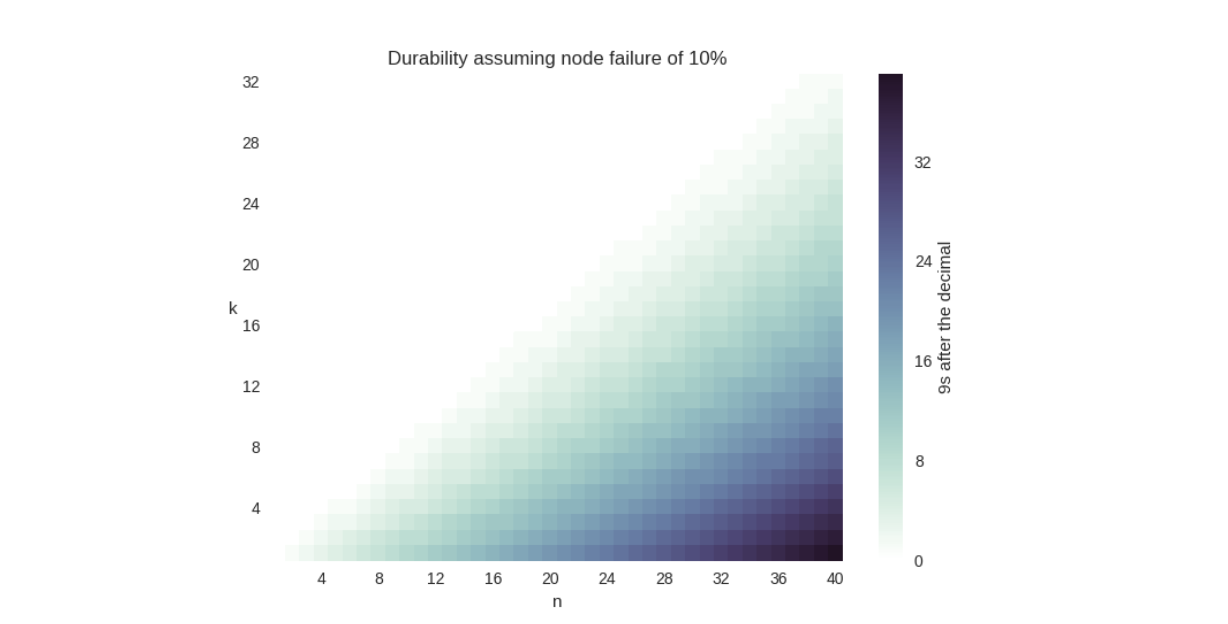
Admittedly, this graph is a little disingenuous: the chances of you caring about having thirty-two 9s of durability is… low, to say the least. The National Weather Service estimates the likelihood of you not getting hit by lightning this year at only six 9s after all. But you should still be able to see that a k = 2, n = 4 is less durable than a k = 16, n = 32 configuration.
In contrast, replication requires significantly higher expansion factors for the same durability. The following table shows durability with a replication scheme:

Comparing the two tables, notice that replicating data at 10x can’t beat erasure codes with k = 16, n = 32, which is an expansion factor of only two. For durable storage, erasure codes simply require ridiculously less disk space than replication.
If you want to learn more about how erasure codes work, you can read this introductory tutorial co-written by some of our team members in 2017.
Okay, erasure codes take less disk space. But isn’t repairing data more expensive?
It’s true that replication makes repair simpler. Every time a node is lost, only one of the remaining nodes is necessary for recovery. On the flip side, erasure codes require several nodes to be involved for each repair. Though this feels like a problem, it’s actually not.
To understand why, let’s set up both scenarios, replication at 9x and erasure codes at k = 18, n = 36, and consider what it costs us. These numbers are chosen because they have similar durability (9x replication has six 9s of durability assuming 10% of node churn, and k = 18, n = 36 erasure coding has seven). We’ll consider what happens when we are storing a data block that is 18 MB and we suddenly lose one-third of our nodes.
At 9x, replication in our model of course has an expansion factor of 9. Once again, replication is the simplest to implement. If we lose one-third of our nine nodes we will need to spin up three new nodes. Each new node transfers a copy of the lost data, which means that each node must transfer 18 MB. That’s a total of 54 MB of bandwidth usage for repair. No intensive CPU processing was needed.
With k = 18, n = 36 erasure codes (with an expansion factor of only two), losing one-third of our nodes means we now only have 24 nodes still available and need to repair to twelve new nodes. The data each node is storing is only 1 MB each, but eighteen nodes must be contacted to rebuild the data. Let’s designate one of the nodes to rebuild the data. It will download eighteen 1 MB pieces, reconstruct the original file, then store the missing twelve 1 MB pieces on new nodes. If this designated node is one of the new nodes, we can avoid one of the transfers. The total overall bandwidth used is at most 30 MB, which is almost half of the replication scenario. This advantage in bandwidth savings becomes even wider with higher durabilities.
Downsides?
Erasure coding did require more CPU time, that’s true. Still, a reasonable erasure encoding library can generate encoded data at at least 650 MB/s, which is unlikely to be the major throughput bottleneck over a wide-area network with unreliable storage nodes.
Erasure coding also required a designated node to do the repair. While this complicates architectures in untrusted environments, it is not an unsolvable problem. It simply requires the addition of hashes, signatures, and retries in a few new places. This is something we’ll talk about more down the road. We have a lot of blog posts to write!
Notably, erasure coding does not complicate streaming. Remember how I said erasure codes are used for satellite communication and CDs? As long as erasure coding is batched into small operations, streaming continues to work just fine. See Figure 4.2 and sections 4.1.2 and 4.8 in our white paper for more details about how we can pull native video streaming off.
Upsides?
Comparing 9x replication and k = 18, n = 36 erasure coding, the latter uses less than half the overall bandwidth for repair. It also uses less than a third of the bandwidth for storage and takes up less than a third of the disk space. It is roughly ten times more durable! Holy crap!
Oh, and did I mention this also enables us to pay storage node operators more? Specifically over three times more? Because the disk-space usage is more efficient, there is more money available for each storage node operator. The income is less diluted across storage nodes, you could say.
It’s worth re-reading those last two paragraphs. These gains are significant. Hopefully by this point you’re convinced that erasure codes are better.
In this edition we dive deeper into why nodes joining and leaving the network - also known as churn - has a much more significant (and also bad) impact on a redundancy strategy that relies on replication. We make the case that using replication in a high-churn environment is not only impractical, but inevitably doomed to fail. Quoting Blake and Rodrigues, “Data redundancy is the key to any data guarantees. However, preserving redundancy in the face of highly dynamic membership is costly.”
An Aside on Dynamics
Before diving into the exciting math parts, we need to quickly define a couple of concepts relating to network dynamics. The lifetime of a node is the duration between it joining and leaving the system for whatever reason. A network made of several nodes has an average lifetime, commonly called the mean time to failure (MTTF). The inverse of mean time to failure is churn rate or frequency of failure-per-unit-of-time. It’s an important relationship to understand, especially when MTTF is a unit of time much greater than the units needed for a specific problem.
Distributed storage systems have mechanisms to repair data by replacing the pieces that become unavailable due to node churn. However, in distributed cloud storage systems, file repair incurs a cost for the bandwidth utilized during the repair process. Regardless of whether file pieces are simply replicated, or whether erasure coding is used to recreate missing pieces, the file repair process requires pieces to be downloaded from available nodes and uploaded to other uncorrelated and available nodes.
After reading part one of this series, it’s clearly not feasible to rely on replication alone, but some projects have proposed combining erasure coding and replication. Once you’ve erasure coded a file and distributed it across a set of nodes, it’s going to have a defined durability for a given level of node churn. If you want to increase that durability for that given level of node churn, you have two choices: increase the erasure code k/n ratio or use replication to make copies of the erasure coded pieces. These two strategies are very different and have a huge impact on the network beyond just increasing durability.
Our Hypothetical Networks
So, let’s define two hypothetical distributed storage networks, one using erasure coding alone for redundancy (the approach used on Storj’s V3 network), and one using erasure coding plus replication for redundancy (which is the approach used by Filecoin as well as the previous, depreciated Storj network). We will assume nodes on both networks are free to join and leave at any time, and that uptime for nodes can be highly variable based on the hardware, OS, available bandwidth, and a variety of other factors. When a node leaves a network, the pieces of data on that node become permanently unavailable. Of course, if nodes fall below a certain threshold of availability in a given month, the impact on the overall availability of files is effectively equivalent to the node leaving the network altogether.
Let’s also assume both hypothetical networks use a 4⁄8 Reed-Solomon erasure code ratio and have 99.9% durability with node churn at 10%. Both networks want to achieve eleven 9s of durability though. One is going to achieve it through erasure coding alone, and the other is going to combine erasure coding with replication.
And Now, Some Math
As it turns out, if you know the target durability, you know the MTTF for nodes, and you know the erasure coding scheme, you can calculate the amount of data churn in a given time period. The formula for calculating data churn is:
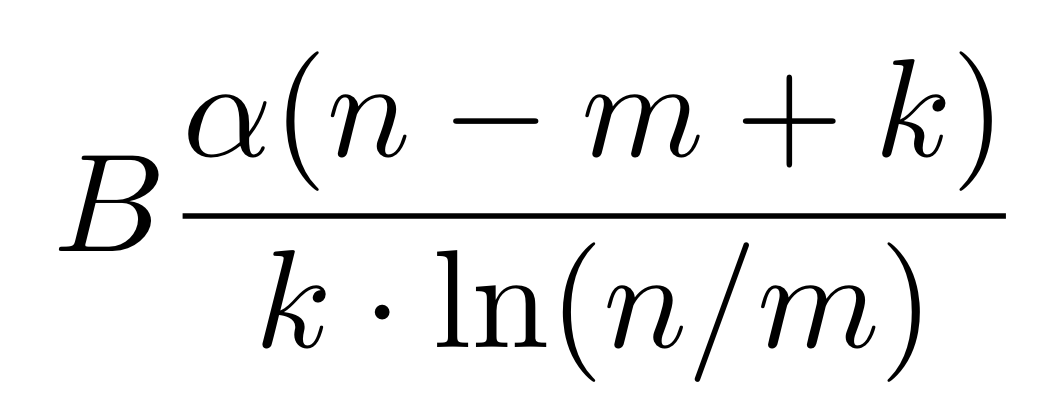
where is the churn rate, B is the number of bytes on the network, n is the total number of erasure shares, m is the repair threshold, and k is the number of pieces needed for rebuild.
For example, on our hypothetical erasure-coding network, even if we use a 30⁄80 Reed-Solomon scheme (which is much more durable than the 4⁄8 scenario listed above), a MTTF of 9 months would mean you would have to repair 35% of your data every month to achieve a durability of 99.999999999%!
This shows node churn is the single most impactful factor in file availability. Increasing node churn dramatically decreases file availability and durability. Strategies like erasure coding and replication are means of insulating against the impact of node churn, but without a mechanism to replace the data, file loss is simply a factor of the rate of churn.
So, let’s take that math and apply it to our two hypothetical networks. The first thing we need to do is calculate how we get to eleven 9s of durability for each of the two scenarios:
For the erasure code-only scenario, calculate the k/n ratio that will deliver the target durability for the defined rate of churn.
For the erasure code+replication scenario, calculate the number of times the erasure coded pieces need to be replicated to deliver the target durability for the defined rate of churn.
To calculate the durability of a replicated or erasure-coded file, we consider the CDF of the Poisson distribution, given by the formula:
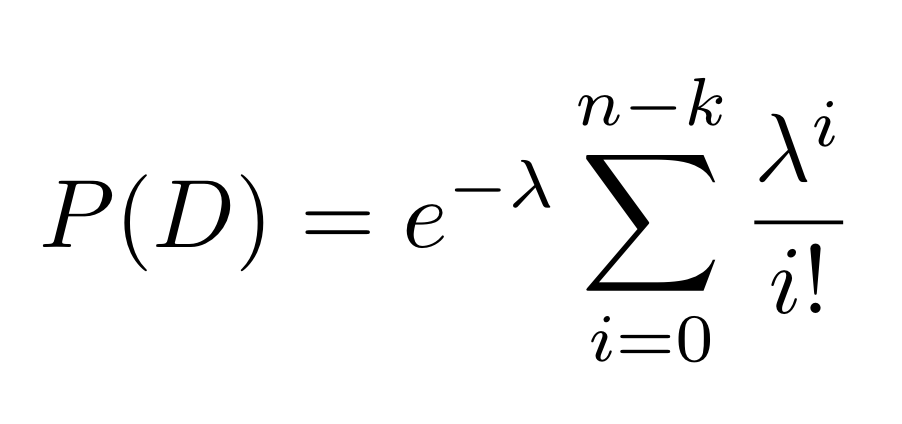
where D is the event that the most n-k pieces have been lost. In the case of simple replication, k=1, so a file is still recoverable when at most n-1 of the pieces have been lost; that is, if at least one of the copies is still on the network, the data is still accessible. When considering replication on a file that has already been subjected to erasure encoding, the calculation changes.
Suppose that a file undergoes k=4, n=8 erasure-encoding (where 8 pieces are created and only 4 are needed for a rebuild), and then suppose further that each of the 8 erasure shares are replicated r=10 times each, for a total of 80 pieces. These 80 pieces are special in that not any 4 can be used to rebuild the file, so they should really be thought of as 80 pieces contained in 8 sets of 10 copies each. To rebuild a file, 4 of the sets must still each have at least 1 piece each.
Thus, rather than having a single factor of P(D) determining the durability (with at most n-1 pieces being lost), one has a factor of P(D) for each unique set required for rebuild, since there are now k sets of which each one must not have lost more than r-1 pieces, where the expansion factor r determines the number of copies that are made (with there being r-1 copies made to achieve an expansion factor of r, including the original file). Calculating this probability requires the use of the Binomial distribution, where we let p be the probability that at most r-1 copies have been lost from a set. Then, to calculate the probability that there are at least k sets containing at least 1 copy each, we find the area of the upper tail of the Binomial CDF:
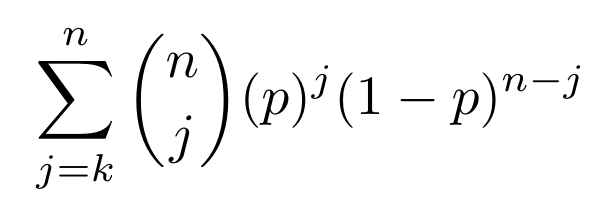
Let’s first look at the impact of node churn on durability based on the two hypothetical scenarios, one using replication+erasure coding, and the other optimizing for erasure coding alone. Based on the above formulas, the results are as follows:

As it turns out (predictably) the increased durability can be achieved in the erasure-code-only scenario with no increase in expansion factor. Adding replication to already-erasure-coded data is much more efficient that just straight up replicating the original file, (which requires 17 copies to achieve), but has triple the expansion factor of erasure codes alone.
In an environment where churn is even higher, or highly variable, durability is impacted significantly in either scenario:
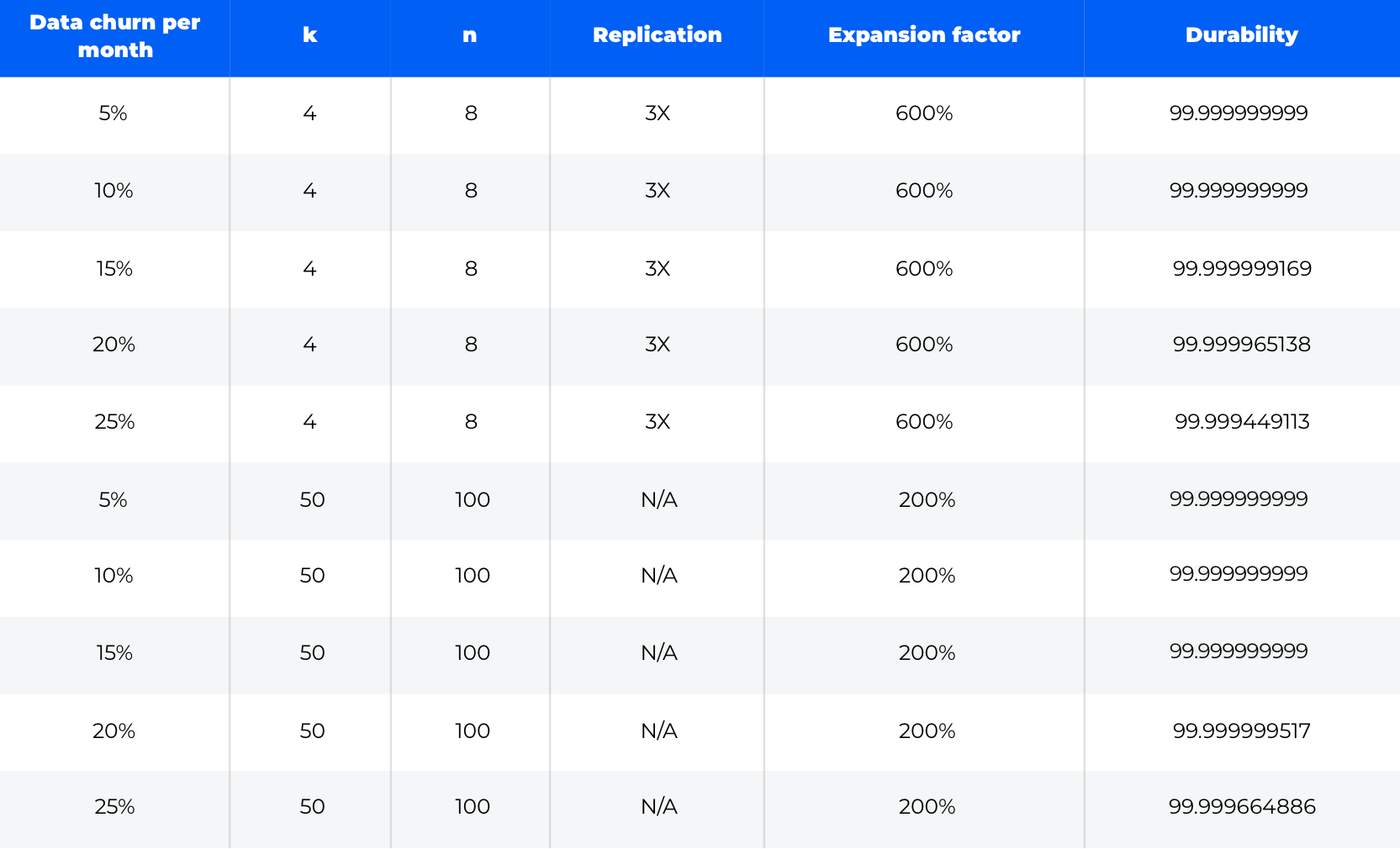
In these unpredictable or highly variable environments, it becomes necessary to address the worst case scenario in order to maintain a constant level of durability. Again, as is clear from the table below, node churn has a massive impact, and when using replication, that massive impact translates directly into increases in the expansion factor. In the table below you can see the impact of churn on expansion factor when trying to maintain a minimum durability of eleven 9s:
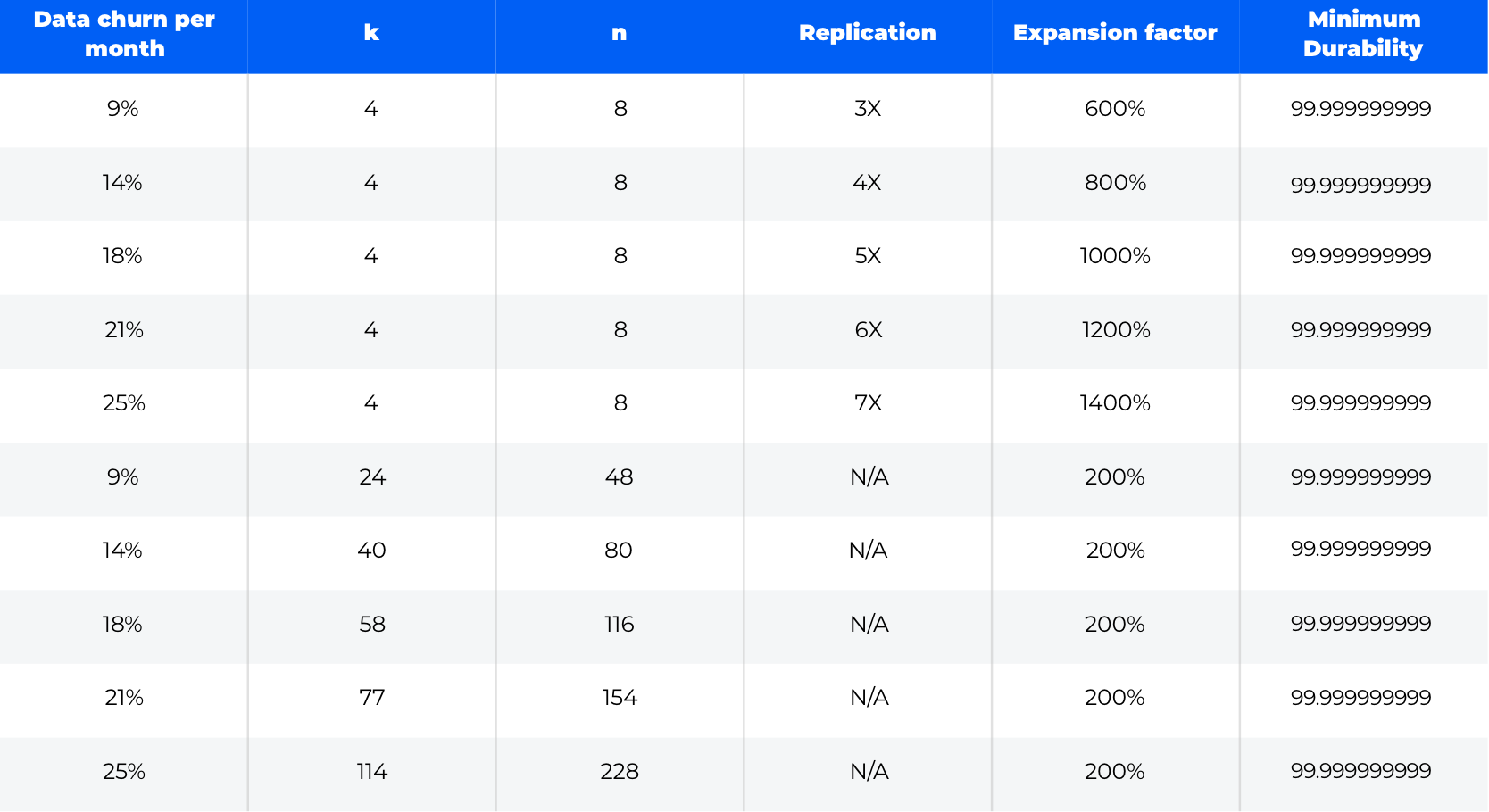
So, what do these tables tell us? Well, there are a number of interesting observations to be drawn:
At higher rates of churn, replication dramatically increases the expansion factor and, as we learned in this blog post, requires much higher bandwidth utilization for repair.
Erasure coding can be used to achieve higher rates of durability without increasing either the expansion factor or the amount of bandwidth used for repair.
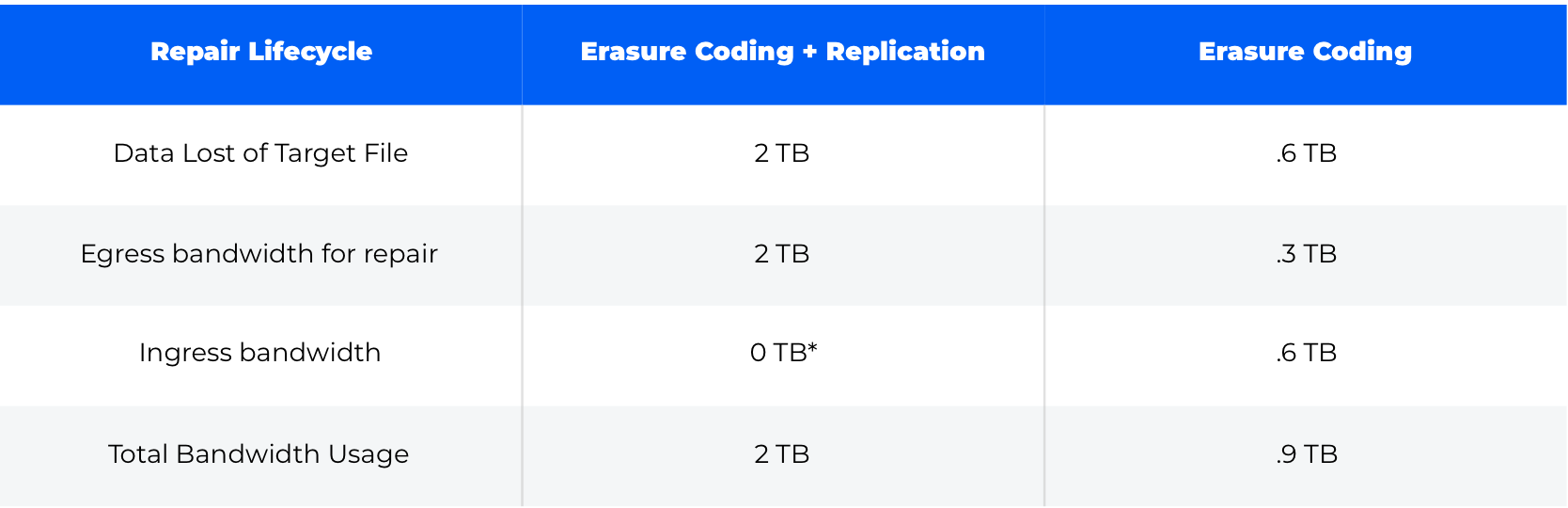
Just to drive that point home, let’s first look at how a file actually exists on the two hypothetical networks:
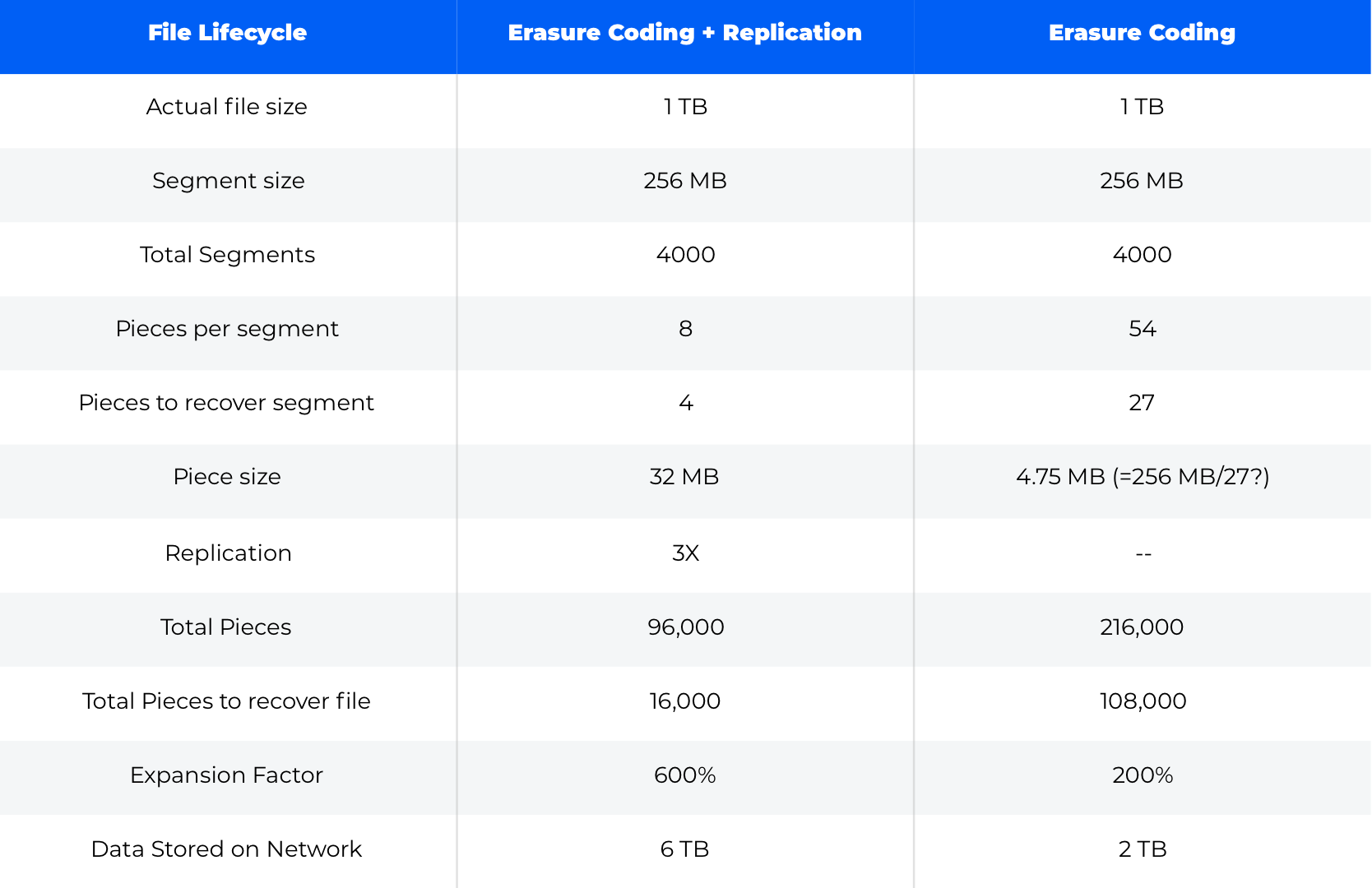
It is worth understanding the differences in how repair actually behaves on our two networks, because the process for replication is very different compared to erasure codes. Continuing the example of the 1 TB file above, let’s examine how repair actually looks when 1⁄3 of nodes storing the data exit the network:
One other important thing to remember about distributed storage networks is that the amount of data the network can store isn’t constrained by the amount of available hard drive space on the nodes. It’s constrained by the amount of bandwidth available to nodes. Allow me to explain.
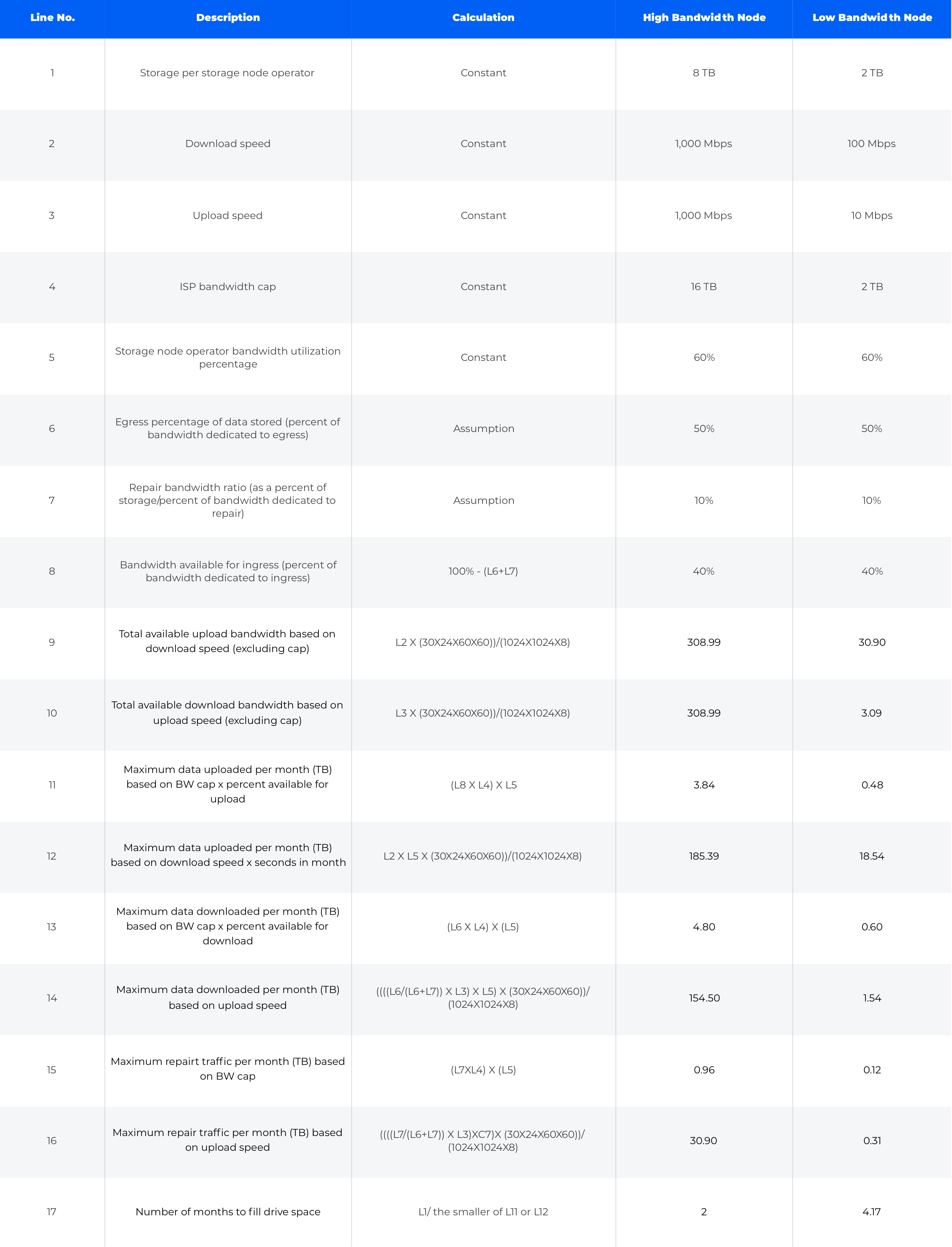
The following variables and calculated values are used in determining the amount of data and bandwidth a storage node operator can contribute:
Variables
Storage per storage node operator - The amount of hard drive space available to share by a storage node.
Download speed - The downstream bandwidth available on the network on which the storage node is operating, measured in Mbps.
Upload speed - The upstream bandwidth available on the network on which the storage node is operating, measured in Mbps.
ISP bandwidth cap - The maximum amount of bandwidth a storage node operator can utilize in a month before being subjected to a bandwidth cap enforcement action such as incurring a financial penalty or being subjected to bandwidth throttling from an ISP.
Storage node operator bandwidth utilization percentage - The percentage of the total monthly bandwidth cap that a user will dedicate to be used by their storage node, assuming some percentage of bandwidth will be utilized for other services.
Egress bandwidth percentage - The average amount of egress traffic from client downloads based on the use cases we support.
Repair bandwidth ratio (as a percent of storage) - The percentage amount of repair traffic on the network, primarily driven by node churn, software or hardware failure. While actual nodes may experience higher or lower repair traffic based on the pieces they hold, this is the average across the network.
Ingress bandwidth percentage - The amount of bandwidth available for uploads of new data from clients.\
Calculations
Total available upload bandwidth based on download speed (excluding cap) - The maximum amount of data available for ingress, based on download speed in Mbps multiplied by number of seconds in a month.
Total available download bandwidth based on upload speed (excluding cap) - This calculation is the percent of the bandwidth cap a user is willing to dedicate to the Storj network multiplied by the bandwidth cap for ingress.
Maximum data uploaded per month (TB) based on BW cap x percent available for upload - This calculation is the amount of data that can be uploaded irrespective of the cap, based on download speed in Mbps multiplied by seconds in a month.
Maximum data uploaded per month (TB) based on download speed x seconds in month - This calculation is the percent of the bandwidth cap a user is willing to dedicate to the Storj network multiplied by the bandwidth cap.
Maximum data downloaded per month (TB) based on BW cap x percent available for download - This calculation is the amount of data that can be downloaded irrespective of the cap, based on upload speed in Mbps times seconds in a month.
Maximum data downloaded per month (TB) based on upload speed - This calculation is the percentage of the bandwidth cap required to dedicate to Storj repair traffic times the bandwidth cap.
Maximum repair traffic per month (TB) based on BW cap - This calculation is the amount of data for repair traffic irrespective of the cap based on upload speed in Mbps times seconds in a month.
Maximum repair traffic per month (TB) based on upload speed - This is how many months it will take to fill the available hard drive space at the lesser ingress rate of percent of available BW cap or actual throughput.
Although download speed is typically higher in asynchronous internet connections, from the perspective of a person uploading a file to, or downloading a file from, a decentralized file system, the upload and download from the client’s perspective are the inverse of the storage node. For example, when a client uploads data to the network, it is technically downloaded to the storage node. Similarly, when data is downloaded by a client, it is technically being uploaded by the storage node.
The following examples are based on two different storage nodes with different bandwidth caps. Note that the amount of data stored is inclusive of the expansion factor.
Bandwidth has a significant impact across the board. It’s generally finite and has to be split between ingress, egress and repair. As the expansion factor increases, the actual amount of bandwidth consumed for those functions increases at the same rates. Lower bandwidth caps further lower the actual amount of data the network can store with a given number of nodes. Increase the amount of bandwidth required for file repair and that number gets lower still.
Let’s look at the impact on bandwidth available for repair if you also constrain nodes practical limits of shared storage space. In the scenario above where nodes have:
2 TB bandwidth cap
100 Mbps down/10 Mbps up asynchronous bandwidth
2 TB of shared storage on average
50% of data downloaded per month
40% data uploaded per month
10% churn
Nodes operate at 100% bandwidth capacity and storage
Each node has less than 0.12 TB of bandwidth available for repair. And that’s in an environment storing archival data without a lot of download bandwidth. When scaling that distributed storage network up to an exabyte of data stored, you really see the impact of the expansion factor.
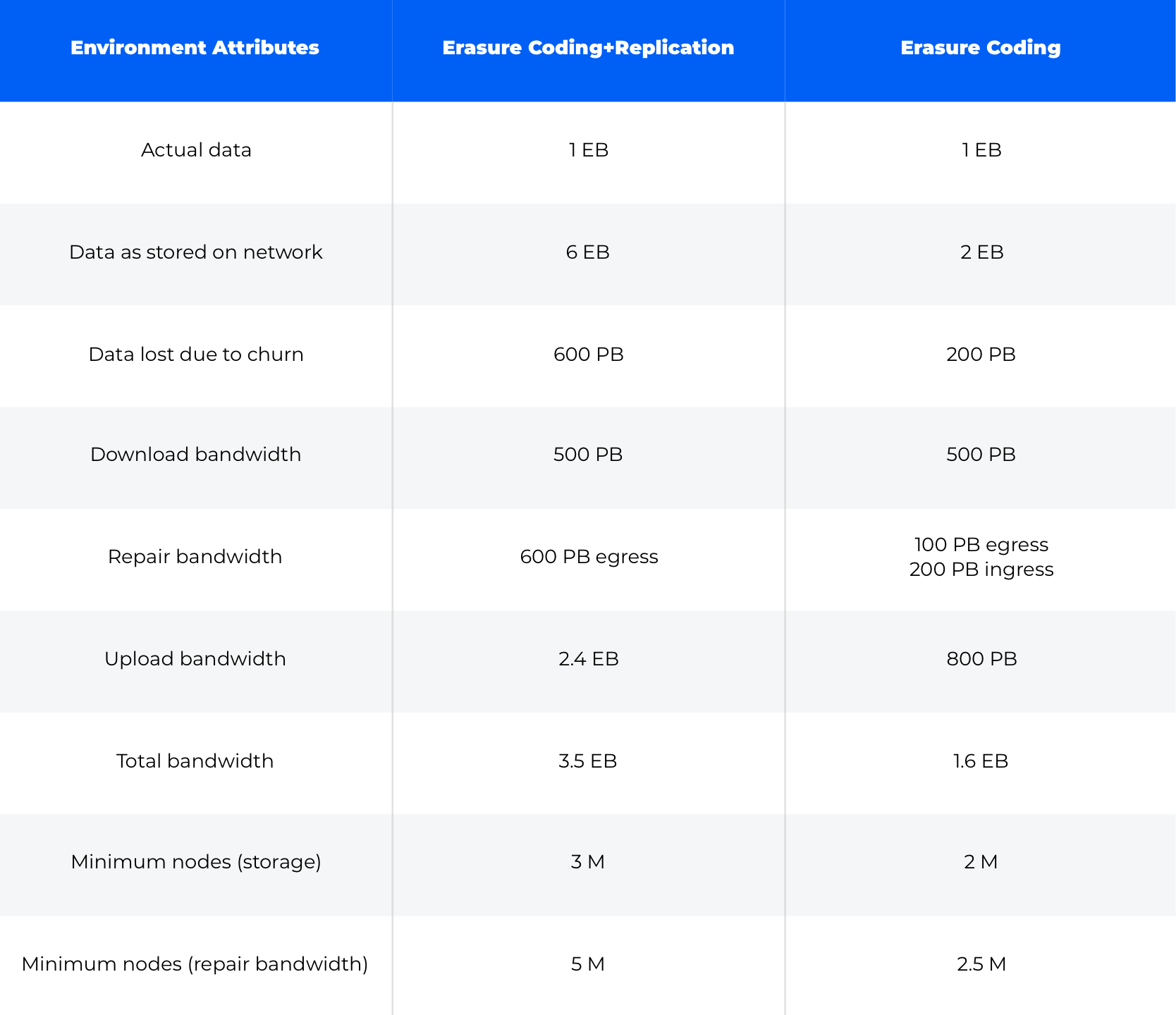
Ultimately, the result is an exponential increase in the number of nodes required to support a given network size. Higher bandwidth use cases further exacerbate the problem by increasing the number of nodes required to service a given amount of stored data. That given network size has a finite amount of revenue associated with it, which is then spread over an increasing number of storage node operators, meaning that over time the amount of money earned by storage node operators decreases.
Rapidly increasing demand for more storage node operators, combined with decreasing payouts per node, results in increased node churn, which only accelerates the cycle. Once again, increased churn increases the expansion factor from replication, increasing bandwidth utilized for repair, which further erodes the bandwidth available for storage and egress.
What this means is that in the debate over any reliance on replication versus erasure coding alone, in an environment that must relentlessly optimize for bandwidth conservation, erasure coding without replication is the clear winner. Replication, and proof-of-replication approaches like that used in the Filecoin network, simply cannot sustain an acceptable level of durability with a corresponding expansion factor and repair rate that can operate in a bandwidth constrained environment. Just imagine that same network above with 25% churn where the replication example requires a 1,400% expansion factor to maintain sufficient durability. Sorry if I scared you with that one.
When you have to factor in the reality that in the current storage market customers only pay for storage based on the actual, pre-erasure coded or replicated volume of data, and egress bandwidth, when it comes to the dollars, replication makes even less sense.